In this section we are going to explain some of the key mathematical properties of mixed model. Before we begin please note that as said before mixed models can become fairly complex, with a variety of parametrization techniques that go beyond the scope and time frame of this chapter. Here I assume that the reader has relatively a good understanding of Ordinary Least Squares regression (OLS) as we are going to use that to build mixed models.
Ordinary Least Squares regression
Ordinary Least Squares (OLS) is a fundamental method for linear regression analysis. It aims to find the line (or hyperplane) that best fits a set of data points by minimizing the sum of the squared differences (residuals) between observed values and the values predicted by the linear model.
Mathematical Formulation
Consider a dataset with \(n\) observations and \(p\) predictors. The model can be expressed as:
\[
y = X\beta + \epsilon
\]
Where:
\(y\) is an \(n \times 1\) vector of observed values.
\(X\) is an \(n \times p\) matrix of predictor variables, often augmented with a column of ones to include the intercept in the model.
\(\beta\) is a \(p \times 1\) vector of coefficients that we want to estimate.
\(\epsilon\) is an \(n \times 1\) vector of the model’s residuals or errors.
The objective of OLS is to minimize the sum of squared residuals, given by:
\[
S(\beta) = (y - X\beta)^\top (y - X\beta)
\]
To find the value of \(\beta\) that minimizes \(S(\beta)\), set the gradient of \(S\) with respect to \(\beta\) to zero. This yields the normal equations:
\[
X^\top X \beta = X^\top y
\]
Assuming \(X^\top X\) is non-singular (invertible), the solution for \(\beta\) is:
\[
\beta = (X^\top X)^{-1} X^\top y
\]
This solution provides the best linear unbiased estimates of the coefficients under the Gauss-Markov theorem, provided the residuals \(\epsilon\) are uncorrelated with constant variance (homoscedasticity) and mean zero.
OLS has some highly desired statistical properties:
Unbiasedness:\(E(\beta) = \beta\), meaning that the expected value of the OLS estimator equals the true parameter value.
Efficiency: Under the assumptions of the Gauss-Markov theorem, the OLS estimator has the smallest variance among all linear unbiased estimators.
Consistency: As the sample size \(n\) approaches infinity, the OLS estimator converges in probability to the true parameter value, assuming the predictors \(X\) are non-stochastic.
Correlated residuals
The classical OLS method is designed under the assumption that the residuals \(\epsilon\) are uncorrelated and homoscedastic. However, when these assumptions are violated, particularly in the presence of correlated residuals, OLS estimates remain unbiased but lose efficiency, meaning they no longer have the smallest possible variance among all linear unbiased estimators.
Consider the linear model: \[
y = X\beta + \epsilon, \quad \text{where} \quad \epsilon \sim N(0, \sigma^2 V)
\]
Assuming that the residuals are not correlated, \(V\) is an identity (The diagonal entries are 1, the rest are zero). However, when the correlation exist we are dealing with a more complex covariance matrix \(V\). The presence of correlated residuals necessitates a transformation of the model so that the assumptions of OLS are effectively restored. This transformation can be achieved through the use of a matrix \(C\), such that when applied to the residuals, results in uncorrelated residuals with uniform variance.
So formally what we are interested in is:
\[
\text{Cov}(C\epsilon) = \sigma^2 I
\] So let’s start working with \(\text{Cov}(C\epsilon)\). Please remember that the mean of the residuals are assumed to be zero. Therefore we can write the covariance equation as \[
\text{Cov}(C\epsilon) = C\epsilon(C\epsilon)^T
\] If we rewrite this and apply the transpose we end up with
\[
\text{Cov}(C\epsilon) = C\epsilon\epsilon^TC^T
\] As we said the original covariance of \(\epsilon\) is \(\sigma^2 V\) so we can replace \(\epsilon\epsilon^T\) by \(\sigma^2 V\):
\[
\text{Cov}(C\epsilon) = C\sigma^2 VC^T = \sigma^2 I
\] If we define both side by \(\sigma^2\)
\[
C VC^T = I
\] We assume that C exhibits complex conjugate symmetry then
\[
\text{Cov}(C\epsilon) = C VC
\]
We take \(C\) to the other side of the equation:
\[
CV= C^{-1}
\] We do the same thing for the other \(C\):
\[
V= C^{-1}C^{-1}
\] Multiply two \(C^{-1}\):
\[
V= C^{-2}
\] Take the inverse of both side \[
V^{-1}= C^{2}
\] and finally we take the square root of both side:
\[
C=V^{-1/2}
\] So let’s put this back in the original equation \[
\text{Cov}(C\epsilon) = C\sigma^2 VC^T = V^{-1/2}\sigma^2 VV^{-1/2} = \sigma^2 I
\] Now that we have our transformation matrix \(V^{-1/2}\), we should apply it to the OLS equation. In order to effectively “whitens” the errors we are going to premultiply OLS equation with the transformation \(V^{-1/2}\):
\[
V^{-1/2} y = V^{-1/2} X \beta + V^{-1/2} \epsilon
\]
With the transformed model \(V^{-1/2} y = V^{-1/2} X \beta + V^{-1/2} \epsilon\) and the transformed errors having covariance \(I\), we can now apply OLS directly:
This is equivalent to estimating beta for Generalized Least Squares (GLS):
\[
\beta_{\text{GLS}} = (X^\top V^{-1} X)^{-1} X^\top V^{-1} y
\] with the following minimization problem:
\[
\min_{\beta} (y - X\beta)^\top V^{-1} (y - X\beta)
\] We can also try to verify our dervitation of beta by expanding the quadratic form: \((y - X\beta)^\top V^{-1} (y - X\beta) = y^\top V^{-1} y - \beta^\top X^\top V^{-1} y - y^\top V^{-1} X \beta + \beta^\top X^\top V^{-1} X \beta\)
Taking the derivative of this expression with respect to \(\beta\) and setting it to zero gives: \[
-2X^\top V^{-1} y + 2X^\top V^{-1} X \beta = 0
\]
\[
X^\top V^{-1} X \beta = X^\top V^{-1} y
\]
Solving for \(\beta\) yields: \[
\beta = (X^\top V^{-1} X)^{-1} X^\top V^{-1} y
\] This is again the GLS estimator, confirming that it minimizes the quadratic form.
Generalized Least Squares (GLS)
Generalized Least Squares (GLS) is a statistical technique used to estimate the unknown parameters in a linear regression model when the error terms exhibit heteroscedasticity (varying variance) or are correlated. Unlike ordinary least squares (OLS) which assumes that the error terms are homoscedastic (constant variance) and uncorrelated, GLS adjusts for these irregularities by pre-multiplying the model by the inverse square root of the covariance matrix of the errors, \(V^{-1/2}\), or directly incorporating the inverse of the covariance matrix, \(V^{-1}\), into the estimation process. This transformation normalizes the errors, leading to more efficient and unbiased estimates even in the presence of non-ideal error structures. GLS is particularly useful in time series analysis, panel data models, and other contexts where observations are not independent.
Example
Before going forward we want to try whether the equation we derived actually work on not.
Let’s get back to our previous example:
Code
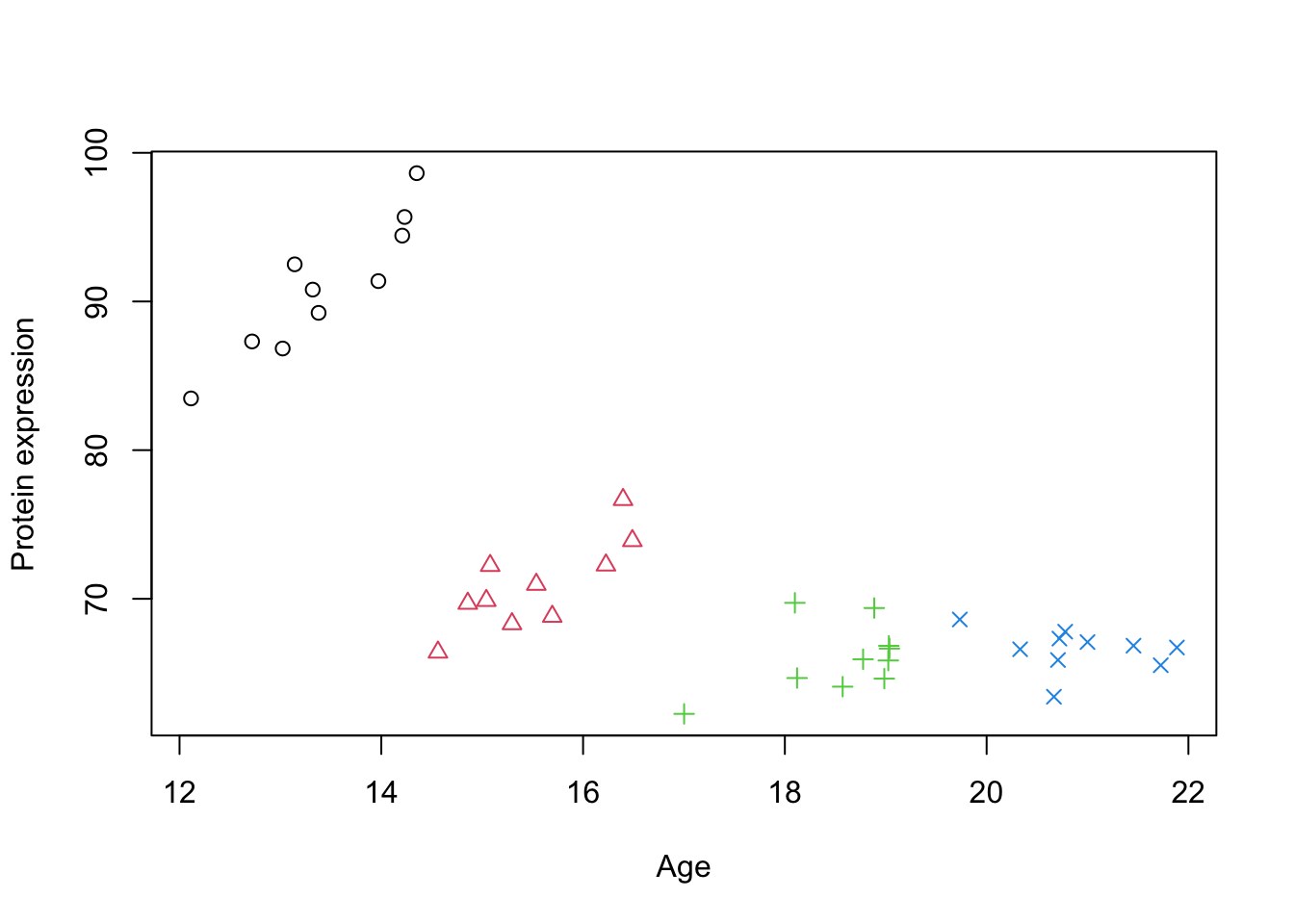
simulate_grouped_trend <-function(group_count =5, points_per_group =10, global_slope =-10, global_intercept =30, group_slope =2, noise_sd =50,noise_sd2=2) {set.seed(123) # Setting a seed for reproducibility# Initialize an empty data frame to store the simulated data data <-data.frame(x =numeric(), y =numeric())# Loop to create each groupfor (i in1:group_count) { x_start <-12+ (i -1) * (10/ group_count) # Stagger the start of x for each group x <-runif(points_per_group, min = x_start, max = x_start + (10/ group_count))# Apply a local positive trend within the group, but maintain the global negative trend local_intercept <- global_intercept + global_slope * (x_start + (10/ (2* group_count))) +rnorm(1, mean =0, sd = noise_sd) y <- local_intercept + group_slope[i] * (x - x_start) +rnorm(points_per_group, mean =0, sd = noise_sd2)# Combine this group with the overall dataset group_data <-data.frame(x = x, y = y,group=i) data <-rbind(data, group_data) }return(data)}# generate simulated datadata_int <-simulate_grouped_trend(group_count =4,points_per_group =10,global_slope =-2,global_intercept =100,group_slope =c(6,4,2,1),noise_sd =5,noise_sd2=2)# set group to factordata_int$group <-factor(data_int$group)# plot the dataplot(data_int$x,data_int$y,xlab="Age",ylab="Protein expression",col=data_int$group,pch=as.numeric(data_int$group))
Figure 2.1: A scatter plot of Age vs. Protein expression
Let’s say that we know the structure of V using some prior knowledge (we will cover how V is exactly derived later).
Code
# Create a diagonal matrix 'var.d' with equal diagonal elements set to 378.6062 (covariance). The dimensions are based on the number of levels in 'data_int$group'.var.d <-diag(378.6062, ncol =length(levels(data_int$group)), nrow=length(levels(data_int$group)))# Transpose of the model matrix for the 'group' variable in the dataset 'data_int', excluding intercept (hence '~0+').Zt <-t(model.matrix(~0+data_int$group))# Compute the variance-covariance matrix 'V' for the random effects using the matrix 'Zt' and the variance diagonal matrix 'var.d'.V <- (t(Zt) %*% var.d %*% Zt)# Set the diagonal elements of the variance-covariance matrix 'V' to 384.5376 (total variance).diag(V) <-384.5376# Construct the model matrix 'X' for the fixed effect 'x' using data from 'data_int'.X <-model.matrix(~x, data=data_int)# Extract the response variable 'y' from 'data_int'.y <- data_int$y# Compute the mixed model solution using generalized least squares, solving the equation (X'V^-1X)^-1X'V^-1y for the fixed effects estimates.print(solve(t(X) %*%solve(V) %*% X) %*%t(X) %*%solve(V) %*% y)
[,1]
(Intercept) 29.910468
x 2.556151
Let’s compare this to when we use mixed model:
Code
library(lme4)model_lmm <-lmer(y ~1+x+(1|group), data = data_int)print(model_lmm)
Linear mixed model fit by REML ['lmerMod']
Formula: y ~ 1 + x + (1 | group)
Data: data_int
REML criterion at convergence: 201.3982
Random effects:
Groups Name Std.Dev.
group (Intercept) 19.458
Residual 2.435
Number of obs: 40, groups: group, 4
Fixed Effects:
(Intercept) x
29.911 2.556
We have calculated the exact same coefficients using both approaches. We can now see how \(V\) changes our data using \(V^{-1/2} y = V^{-1/2} X \beta + V^{-1/2} \epsilon\). But before that we need to cover another small algebraic operation Square root of a matrix or specifically how to calculate V^{-1/2}.
Assuming \(V\) is a symmetric matrix, it can be decomposed into: \[
V = P \Lambda P^T
\] where:
\(P\) is an orthogonal matrix whose columns are the eigenvectors of \(V\).
\(\Lambda\) is a diagonal matrix whose diagonal elements are the eigenvalues of \(V\), denoted as \(\lambda_i\) (i.e., \(\Lambda = \text{diag}(\lambda_1, \lambda_2, ..., \lambda_n)\)).
For \(V\) to have a real square root, all its eigenvalues should be non-negative (\(\lambda_i \geq 0\) for all \(i\)). This is because the square root of a negative number is not defined in the real numbers, which would lead to complex values.
The square root of the diagonal matrix \(\Lambda\) is straightforward to compute. The square root of a diagonal matrix is another diagonal matrix \(\Lambda^{1/2}\) with diagonal entries equal to the square roots of the diagonal entries of \(\Lambda\). Thus: \[
\Lambda^{1/2} = \text{diag}(\sqrt{\lambda_1}, \sqrt{\lambda_2}, ..., \sqrt{\lambda_n})
\]
The square root of the matrix \(V\), denoted \(V^{1/2}\), can now be constructed using the eigenvectors and the square root of the eigenvalues: \[
V^{1/2} = P \Lambda^{1/2} P^T
\] This expression utilizes the original matrix of eigenvectors \(P\), the square root of the eigenvalue matrix \(\Lambda^{1/2}\), and the transpose of \(P\).
To verify that \(V^{1/2}\) is the square root of \(V\), compute \(V^{1/2} V^{1/2}\) and check that it equals \(A\): \[
V^{1/2} V^{1/2} = (P \Lambda^{1/2} P^T) (P \Lambda^{1/2} P^T)
\] Using the orthogonality of \(P\) (i.e., \(P^T P = I\) where \(I\) is the identity matrix):
\[
V^{1/2} V^{1/2} = P \Lambda^{1/2} (P^T P) \Lambda^{1/2} P^T = P \Lambda^{1/2} \Lambda^{1/2} P^T = P \Lambda P^T = V
\] So, \(V^{1/2}\) is the square root of \(V\).
Let’s create a small function in R to calculate the square root of a matrix:
matrix_sqrt <-function(Sigma) {# Ensure the matrix is symmetricif (!all.equal(Sigma, t(Sigma))) {stop("The input matrix must be symmetric.") }# Compute the eigenvalues and eigenvectors eigen_decomp <-eigen(Sigma)# Extract eigenvalues and eigenvectors eigenvalues <- eigen_decomp$values eigenvectors <- eigen_decomp$vectors# Check for negative eigenvaluesif (any(eigenvalues <0)) {stop("The matrix must be positive definite.") }# Compute Lambda^1/2 Lambda_half <-diag(1/sqrt(eigenvalues))# Compute Sigma^1/2 Sigma_half <- eigenvectors %*% Lambda_half %*%t(eigenvectors)return(list(Sigma_half=Sigma_half,eigenvectors=eigenvectors,eigenvalues=eigenvalues))}
Now what we are going to do is to transform \(X\) (the design matrix) and \(y\) (our response) using the \(V^{1/2}\) and only perform OLS on it:
Figure 2.2: A scatter plot of of transformed X and Y
It is clear that the difference between groups has been removed in the transformed data. We can appreciate this procedure more if we try to increase the variance between the groups and see what happens to the transformation:
Code
# fit the modellibrary(ggplot2)library(gganimate)library(dplyr)library(tidyr)library(mvtnorm)global_intercept_slop <- model_lmm@betamax_cov <-378.6062total_variance <-384.5376# Animation Data Preparationresults <-list()for (co inseq(0, max_cov, length.out =20)) { var.d <-diag(co, ncol =length(levels(data_int$group)), nrow =length(levels(data_int$group))) Zt <-t(model.matrix(~0+ data_int$group)) V <- (t(Zt) %*% var.d %*% Zt)diag(V) <- total_variance V_inv_sqrt <-matrix_sqrt(V)$Sigma_half X <-model.matrix(~x, data = data_int) y <- data_int$y X_transformed <- V_inv_sqrt %*% X y_transformed <- V_inv_sqrt %*% y transformed_data <-data.frame(X_transformed = X_transformed[, 2], y_transformed, Group = data_int$group, co = co) results[[length(results) +1]] <- transformed_data}# Combine all data frames for animationanimation_data <-do.call(rbind, results)# Create the animation using ggplot2 and gganimateggplot(animation_data, aes(x = X_transformed, y = y_transformed, color = Group)) +geom_point()+stat_ellipse(aes(x=X_transformed, y=y_transformed,color=Group),type ="norm")+labs(title ="Variance scaling factor: {closest_state}", x ="Transformed X", y ="Transformed Y") +transition_states(co, transition_length =2, state_length =1) +ease_aes('linear')
Figure 2.3: A scatter plot of of transformed X and Y
By now it should be clear that as the variance across the group is low that transformation does basically nothing (because there is nothing to correct for) but as we increase this variance we keep rescaling and streching the data so that they are aligned and therefore the differences between the groups are minimized.
So this transformation ensures that each dimension (principal component) of the space now has equal variance (specifically, variance of 1), removing the effect of the original variances encoded by \(V\). If the components of the data were correlated (as indicated by the off-diagonal elements of \(V\)), the transformation effectively decorrelates these components. In the new space, the covariance between any pair of different components of \(V^{-1/2} data\) is zero. Thus, geometrically, \(V^{-1/2} data\) transforms the data into a form where the scale differences and correlations introduced by \(V\) are neutralized, making the transformed data suitable for analysis under standard assumptions of independence and uniform scale.
The last thing to note here is that here we are dealing with a random intercept model, the covariance matrix \(V\) used for the transformation typically involves scaling and centering the group data without any rotation. This is because the model structure we are using doesn’t incorporate random slopes or other types of covariance structures that might induce rotation. Instead, it predominantly influences the scaling and translation of the groups in our dataset.
In a random intercept model, each group has its own intercept but shares the slope (if any), leading to vertical shifts in the data but maintaining the same orientation (no rotation) regarding the predictor axis. So geometrically:
Scaling: As we increase the variance parameter (co in our model), the amount of scaling increases. This scaling affects how tightly or loosely the data points within each group are clustered around their group mean.
Centering: The transformation tends to draw group data towards a central axis or point because each group’s variance contributes to pulling the group’s mean towards the overall mean of the dataset.
In terms of matrix operations: - The matrix \(V\) in this case is primarily influencing the variance within each group and does not introduce any off-diagonal terms that would typically cause a rotation. Rotation in the data space would occur if there were covariances between different dimensions (such as would be introduced with random slopes), which would manifest as off-diagonal elements in \(V\).
In order to true see what the transformation does, we now incorporate a random slope and show it affects the transformation here.
Code
# fit the modelmodel_lmm <-lmer(y ~1+x+(1+x|group), data = data_int)# custome function to extract the V matrixgetV1 <-function(x,var1=344.65503,var2=5.141458,cov=-39.26625,times=4){ Zt <-getME(x, "Zt") vr <-sigma(x)^2 original_matrix <-matrix(c(var1, cov, cov, var2), nrow=2, byrow=TRUE)var.d <-bdiag(rep(list(original_matrix),times)) var.b <-(t(Zt) %*% var.d %*% Zt) sI <- vr * Matrix::Diagonal(nobs(x)) #for a sparse matrix var.y <- var.b + sI}# Animation Data Preparationresults <-list()varr1<-seq(0, 344.65503, length.out =20)varr2<-seq(0, 5.141458, length.out =20)corr<-seq(0, -39.26625, length.out =20)for (ii in1:20) { V<-getV1(x = model_lmm,var2 = varr2[ii],cov = corr[ii],var1 = varr1[20]) V_inv_sqrt <-matrix_sqrt(V)$Sigma_half X <-model.matrix(~x, data = data_int) y <- data_int$y X_transformed <- V_inv_sqrt %*% X y_transformed <- V_inv_sqrt %*% y transformed_data <-data.frame(X_transformed = X_transformed[, 2], y_transformed, Group = data_int$group, co = varr2[ii]) results[[length(results) +1]] <- transformed_data} V<-getV1(x = model_lmm,var2 = varr2[20],cov = corr[20],var1 = varr1[20]) V_inv_sqrt <-matrix_sqrt(V)$Sigma_half X <-model.matrix(~x, data = data_int) y <- data_int$y X_transformed <- V_inv_sqrt %*% X y_transformed <- V_inv_sqrt %*% y transformed_data <-data.frame(X_transformed = X_transformed[, 2], y_transformed, Group = data_int$group, co = varr2[ii])# Combine all data frames for animationanimation_data <-do.call(rbind, results)ggplot(animation_data, aes(x = X_transformed, y = y_transformed, color = Group)) +geom_point()+stat_ellipse(aes(x=X_transformed, y=y_transformed,color=Group),type ="norm")+labs(title ="Variance of slope scaling factor: {closest_state}", x ="Transformed X", y ="Transformed Y") +transition_states(co, transition_length =1, state_length =6) +ease_aes('linear')+geom_smooth(method ="lm",se = F)
Figure 2.4: A scatter plot of of transformed X and Y
In the plot above, i have already applied the random intercept transformation to make it a bit easier to see the rotation.
The slope transformation basically draws the overall slope towards the global one and aligns different groups.
So so summarize \(V\) in GLS transforms the data into a form where the scale differences and correlations introduced by grouping structure (or any other known structure) are neutralized, making the transformed data suitable for analysis under standard assumptions of independence and uniform scale.
Structure of V
I want to remind you here is that the purpose of matrix \(V\) is to encode the correlation structure within each group in the data. Given this, as we said before, in an OLS model, it is typically assumed that the residuals are independently and identically distributed (i.i.d.) with a variance of \(\sigma^2\). This again implies that the covariance matrix of the residuals is: \[
\text{Cov}(\epsilon) = \sigma^2 I
\] where \(\mathbf{I}\) is the identity matrix, indicating no correlation between residuals of different observations.
Suppose we now believe that there is an underlying group structure that impacts the variance of the observations. This is a very important statement. If we don’t believe or know that there is a grouping structure in our experiment as prior knowledge, then our model has the total residual variance \(\sigma^2\). In this context even if the true covariance matrix of the residuals is not diagonal, we will have no way of addressing this simply because we don’t know what grouping structure has caused the dependencies between the residuals. So from now on, we are going to assume that we know there is a grouping in our data so that the difference between these groups whether it is on the slope or intercept adds an additional variance component. For simplicity we will be only talking about random intercept from now but the concept will apply to any sort of structure we decide to add to the model.
So let’ say that we think there is a grouping structure where each group has its specific baseline level of \(y\). The differences between these baselines adds an additional variance component \(\sigma_d^2\) that reflects the variability across the groups beyond what is captured by the base residual variance \(\sigma^2\). As a result we our total variance is now \(\sigma_d^2+\sigma^2\). In this case, \(\sigma^2\) is now the variance of residuals after accounting for grouping structure and \(\sigma_d^2\) is the variance of between the groups.
It should be obvious to see that the relation between between \(\sigma_d^2\) and \(\sigma^2\) should effectively reflect how tightly the data points are clustered within each group. If the variance within groups (i.e., \(\sigma^2\)) is relatively small compared to the variance between groups (i.e., \(\sigma_d^2\)), it indicates that the groups are distinctly different from each other, and that the grouping structure is a significant factor in explaining the overall variability in the data. This scenario would suggest strong clustering within groups, meaning that the observations within each group are similar to each other but differ significantly from observations in other groups. Conversely, if \(\sigma^2\) is large relative to \(\sigma_d^2\), it suggests that the within-group differences are significant, and the grouping structure might not be as influential in explaining the variance in the data.
This relationship helps us define intra-class correlation coefficient (ICC). \[
\text{ICC} = \frac{\sigma_d^2}{\sigma_d^2 + \sigma^2}
\]
In our case ICC describes the degree to which units within the same group resemble each other. It is considered a type of correlation, but it applies to data organized into groups rather than to data consisting of paired observations.
The ICC formula calculates the proportion of total variance (\(\sigma_d^2 + \sigma^2\)) that is due to differences between groups. It essentially measures the ratio of between-group variance to the total variance in the data.
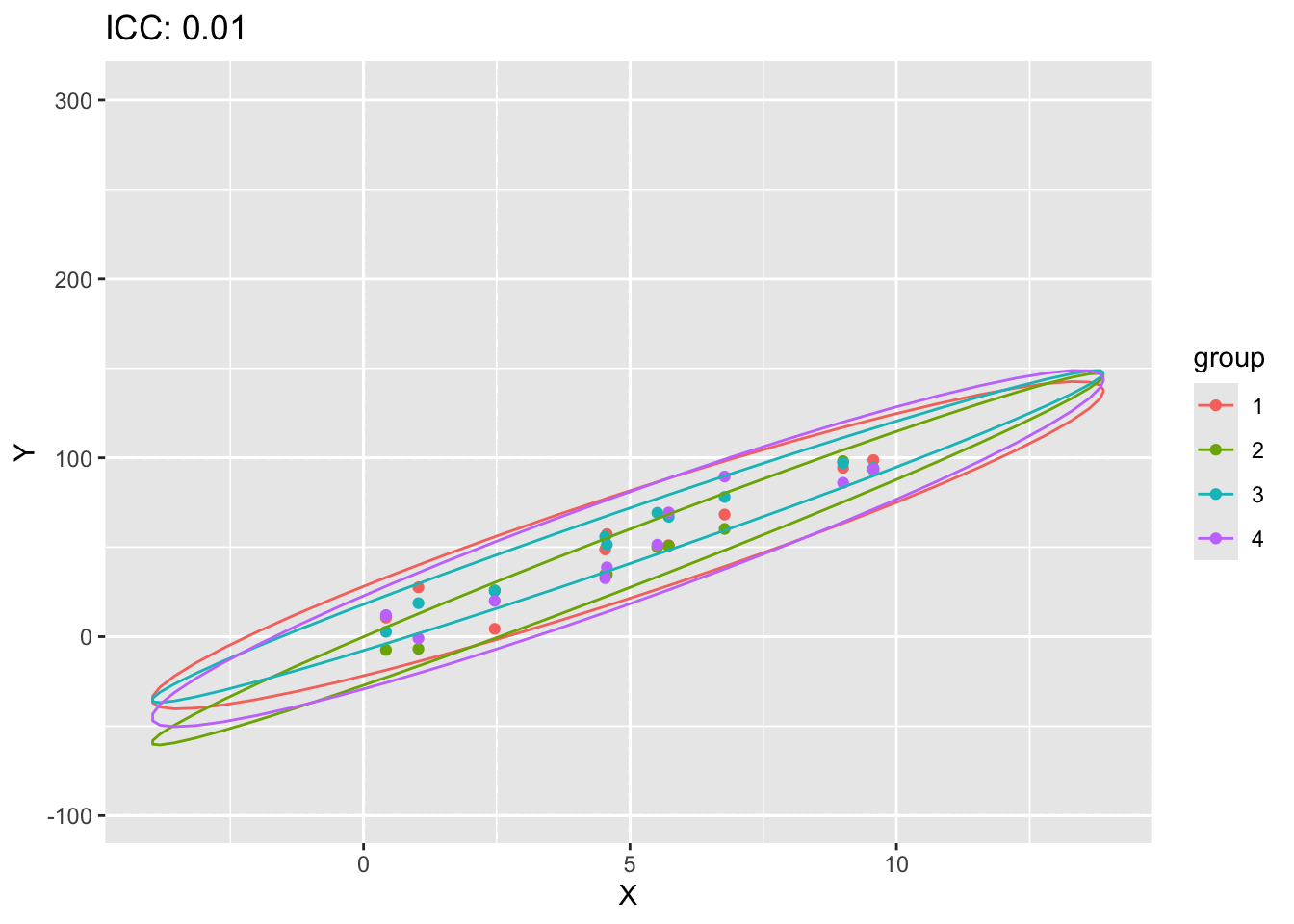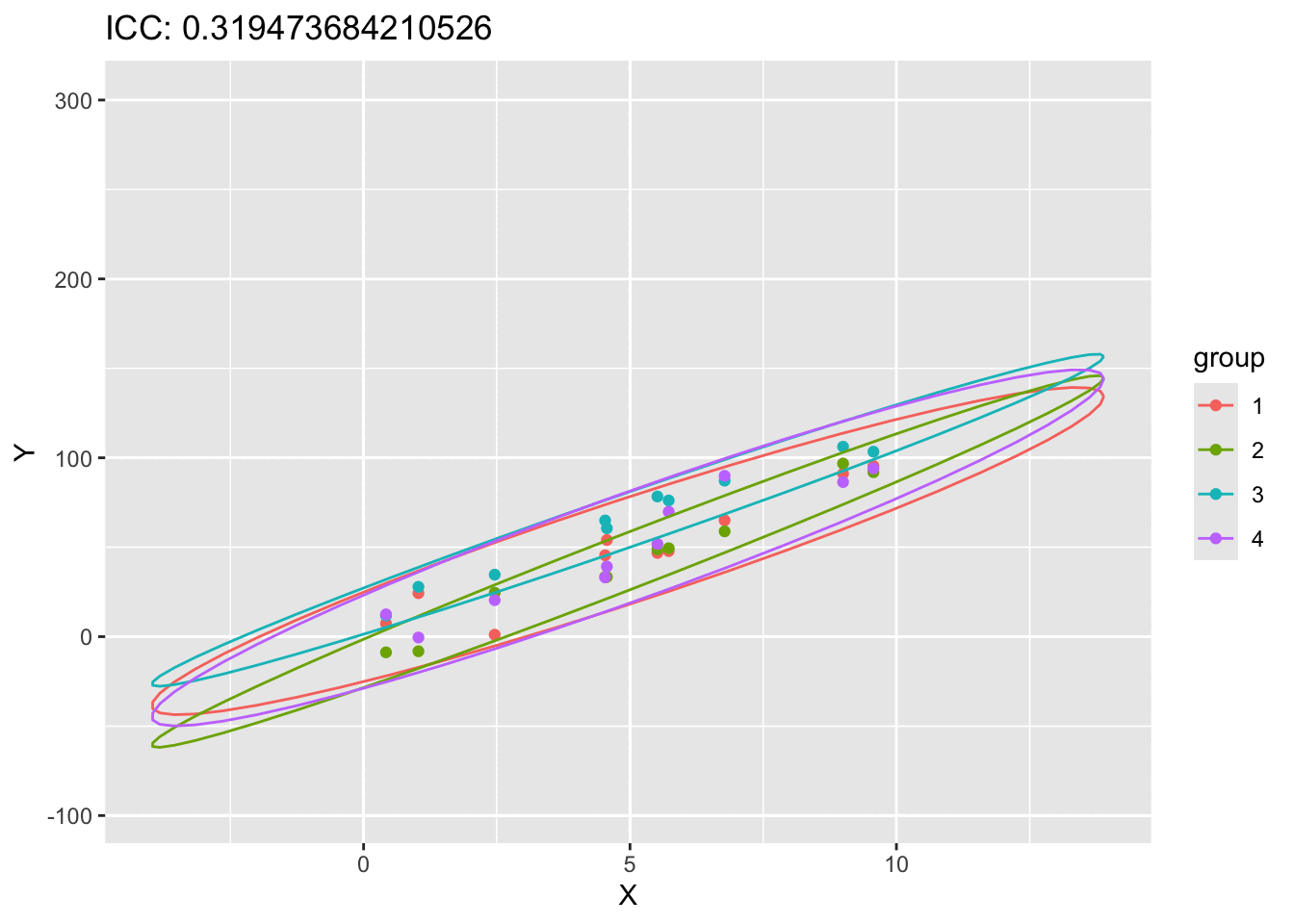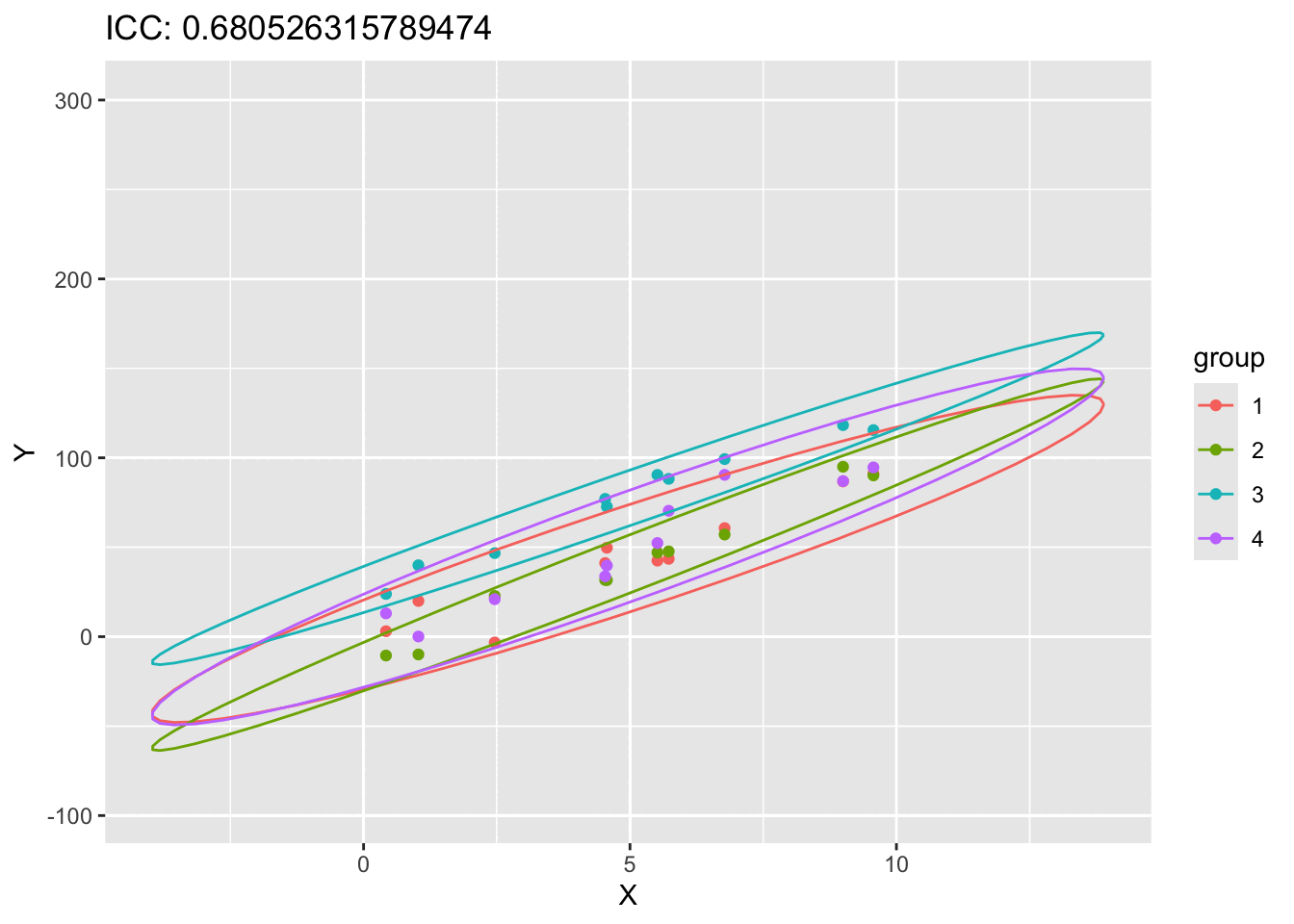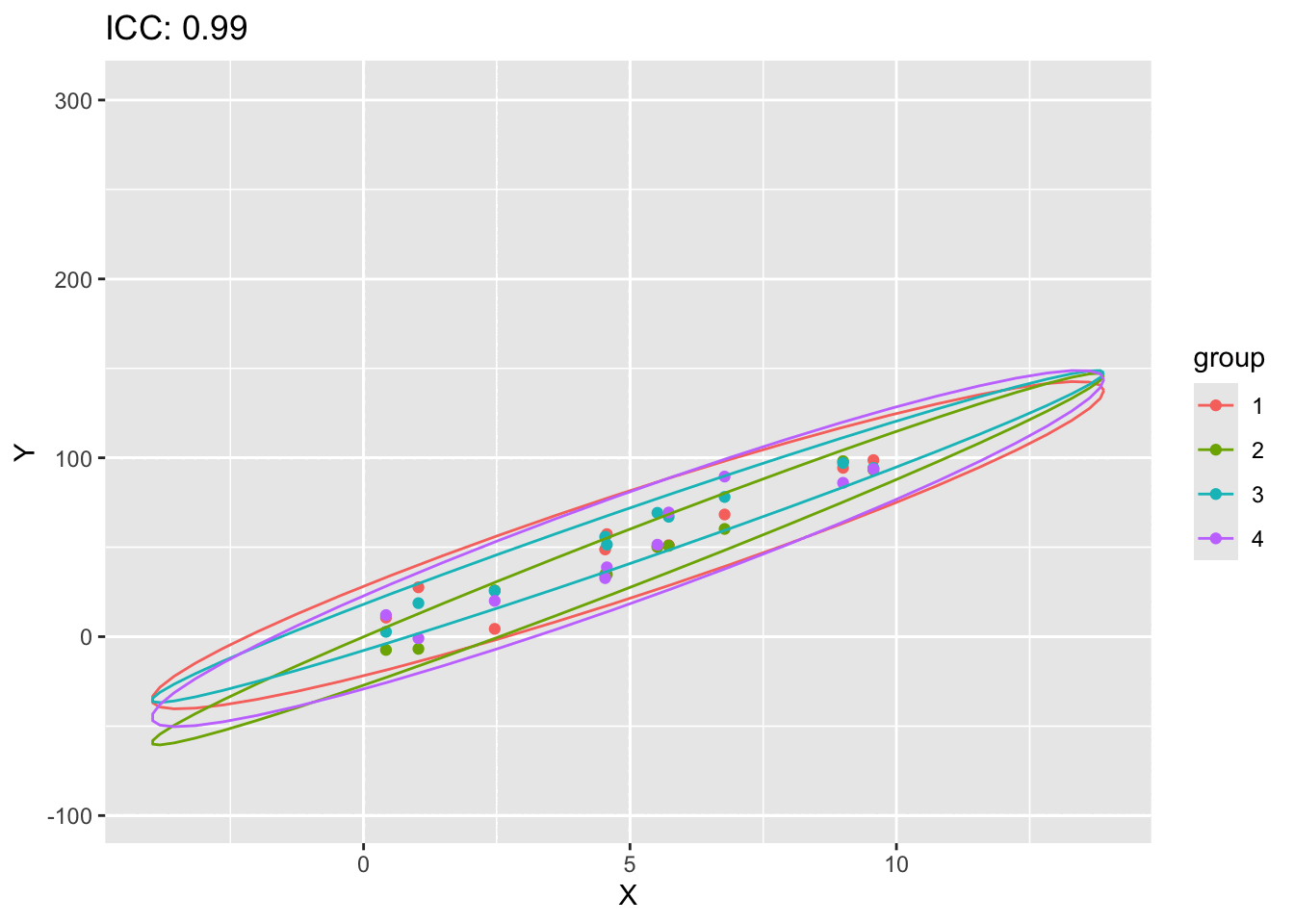
If \(\text{ICC}\) is close to 1, it indicates that most of the variation in the data is due to differences between groups (high between-group variability).
If \(\text{ICC}\) is close to 0, it indicates that most of the variation in the data is due to differences within group (high within-group variability or noise).
We can clarify this using a simple example:
#| code-fold: true#| label: fig-scatter-plot-ICC#| fig-cap: "A scatter plot of of X and Y showing the effect of ICC"# fit the modellibrary(ggplot2)library(gganimate)simulate_data <-function(n_groups, n_per_group, slope, icc, sigma_within) {# Parameters mu <-0# Overall intercept (can be set to other values as needed)# Compute the variance components sigma_between <- icc * sigma_within / (1- icc)# Simulate random effects for each group (intercepts) group_effects <-rnorm(n = n_groups, mean = mu, sd =sqrt(sigma_between))# Prepare data frame data <-data.frame(group =rep(1:n_groups, each = n_per_group),x =rep(runif(n = n_per_group, min =0, max =10), times = n_groups) )# Add the fixed effect (slope) and random effects data$y <- slope * data$x +rep(group_effects, each = n_per_group) +rnorm(n = n_groups * n_per_group, mean =0, sd =sqrt(sigma_within))return(data)}results<-list()data_int <-simulate_data(4,10,10,0.1,100)ICCs<-seq(0.01, 0.99, length.out =20)for (ICC inseq(0.01, 0.99, length.out =20)) {set.seed(123) data_int <-simulate_data(4,10,10,ICC,100) transformed_data <-cbind(data_int,ICC=ICC) results[[length(results) +1]] <- transformed_data}animation_data <-do.call(rbind, results)animation_data$group<-as.factor(animation_data$group)ggplot(animation_data, aes(x = x, y = y, color = group)) +geom_point()+stat_ellipse(aes(x=x, y=y,color=group),type ="norm")+labs(title ="ICC: {closest_state}", x ="X", y ="Y") +transition_states(ICC, transition_length =1, state_length =6) +ease_aes('linear')
It should be clear that as ICC goes up, the data points starts forming more distinct clusters thus increasing the correlation. We have now a method to measure the correlation within a cluster of data points. We can now proceed with defining the structure of \(V\).
We start with the diagonal elements. The diagonal elements must reflect the total variance for each observation within the group, which includes both the baseline residual variance and the additional variance due to the group effect. Thus: \[
\text{Diagonal elements} = \sigma^2 + \sigma_d^2
\] The off-diagonal elements are a little bit more involved. Remember that, off-diagonal elements show the covariance between data points within each group.
Also recall that each observation within a group shares the same variance components therefore \(\sigma_{W_{ij}} = \sigma_{W_{ik}}\). Our total variance was \(\sqrt{\sigma^2 + \sigma_d^2}\) so
Substitute the expressions for \(\rho\) and \(\sigma_{W_{ij}}\) into the covariance formula: \[
\text{Cov}(W_{ij}, W_{ik}) = \frac{\sigma_d^2}{\sigma^2 + \sigma_d^2} \times (\sigma^2 + \sigma_d^2)
\]\[
\text{Cov}(W_{ij}, W_{ik}) = \sigma_d^2
\] Here, the factor \(\sigma^2 + \sigma_d^2\) in the denominator and the standard deviations cancel out, leaving \(\sigma_d^2\).
Given the calculations and the framework we’ve discussed, we can now construct the covariance matrix \(V\) for our generalized least squares model.
In the context of GLS where we recognize the presence of group effects, the covariance matrix \(V\) takes on a block diagonal form. Each block corresponds to a group of data points that share a common variance structure due to their grouping. This form is important as it reflects the within-group correlations while assuming independence between groups.
The matrix \(V\) is composed of blocks \(V_i\) along the diagonal, where each block \(V_i\) is an \(n_i \times n_i\) matrix for group \(i\) (assuming \(n_i\) observations per group). Each block \(V_i\) can be described as follows: \[
V_i = \begin{bmatrix}
\sigma^2 + \sigma_d^2 & \sigma_d^2 & \cdots & \sigma_d^2 \\
\sigma_d^2 & \sigma^2 + \sigma_d^2 & \cdots & \sigma_d^2 \\
\vdots & \vdots & \ddots & \vdots \\
\sigma_d^2 & \sigma_d^2 & \cdots & \sigma^2 + \sigma_d^2
\end{bmatrix}
\]
and factor out \(\sigma^2\) it gives us a general form of \[
\sigma^2 (\mathbf{I} + \frac{\sigma_d^2}{\sigma^2} \mathbf{11'})
\] Giving us the form of \[
\sigma^2V_i = \begin{bmatrix}
1 + \sigma_d^2/\sigma^2 & \sigma_d^2/\sigma^2 & \cdots & \sigma_d^2/\sigma^2 \\
\sigma_d^2/\sigma^2 & 1 + \sigma_d^2/\sigma^2 & \cdots & \sigma_d^2/\sigma^2 \\
\vdots & \vdots & \ddots & \vdots \\
\sigma_d^2/\sigma^2 & \sigma_d^2/\sigma^2 & \cdots & 1 + \sigma_d^2/\sigma^2
\end{bmatrix}
\]
Each diagonal element of \(V_i\) is \(\sigma^2 + \sigma_d^2\), representing the total variance for each observation within the group. This includes both the baseline residual variance \(\sigma^2\)) and the additional variance \(\sigma_d^2\) due to the group effect. Each off-diagonal element is \(\sigma_d^2\), which we derived from the intra-class correlation \(\rho\). These elements represent the covariance between any two different observations within the same group, quantifying how much observations within a group are expected to covary due to the shared group effect.
It is important to note that again \(V\) has the block diagonal form in which each block is \(V_i\). The block diagonal form of \(V\) is appropriate because it reflects that: - Observations within the same group are correlated due to shared group effects, as captured by the off-diagonal elements. - Observations from different groups are assumed to be independent of each other, justifying the separation into different blocks for each group.
We will now finish construction of \(V\) bases on \(V_i\). Please note that the stucture of \(V_i\) (\(\sigma^2 (\mathbf{I} + \frac{\sigma_d^2}{\sigma^2} \mathbf{11'})\)) seems to be identical for any \(i\). This is actually true for our simple cases where we have only a single varying baseline (\(intercept\)) between the groups. In this case we can manually count how many data points are in each group and just create a matrix a looks like this:
\[
V=\begin{bmatrix}
V_1 & 0 & 0\\
0 & \ddots & 0 \\
0 & 0 & V_n
\end{bmatrix}\
\] where \(n\) is the number of groups. We practicaly just copy and paste \(\sigma^2 (\mathbf{I} + \frac{\sigma_d^2}{\sigma^2} \mathbf{11'})\) in each diagonal entire. This however is not an elegant solution. If we have more complex grouping structure with many components, we will have a hard time doing that manually. Here we can use deign matrix. You should be fimilar with a deign matrix but i will try to give a very short overview.
Design matrix
The design matrix, \(Z\), specifies how grouping and effects are associated with observations. Essentially, \(Z\) allocates the influence of effects to the observational data.
Each row of \(Z\) corresponds to an observation in the dataset. Each column of \(Z\) represents a an effect (like intercept or slope). The number of columns in \(Z\) is equal to the number of effects in the model. The elements of \(Z\) indicate the degree to which a given effect influences a particular observation. These elements can be binary (0 or 1) in simple cases or continuous values representing the strength or magnitude of the effect.
To illustrate the use of \(Z\) more concretely, let’s consider a couple of examples from typical applications:
Suppose we have a study measuring blood pressure in patients from different clinics, where each clinic is considered a group. If we model the intercept for each clinic, indicating that each clinic might inherently have higher or lower blood pressure readings:
Each row corresponds to a patient’s measurement, and there is one column for each clinic. Each element in \(Z\) is: - \(1\) if the observation (patient) belongs to the clinic (group) - \(0\) otherwise
Form of \(Z\):
If there are three clinics and six patients (two in each clinic), \(Z\) might look like: \[
Z = \begin{bmatrix}
1 & 0 & 0 \\
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \\
0 & 0 & 1
\end{bmatrix}
\] Each column represents a clinic, and each row assigns a patient to their respective clinic.
For multiple individuals, \(Z\) would block these vectors accordingly, potentially stacking them if each has a separate slope effect.
If we had model both intercept and slope (let’s say age) together we might end up having:
The design matrix \(Z\) is tailored to the structure of the study and the specific effects being modeled. Here we are going to automate building \(V\) using design matrix.
Please Note that Z has also a block diagonal form. Each block \(Z_i\) continues the matrix format by isolating specific subgroups or experimental conditions, which allows for different intercepts and slopes to be applied to separate segments of the data. This design is particularly useful for mixed-effects models where we might want to estimate both fixed effects (common to all groups) and random effects (varying by group or individual).
For example if we consider the matrix \(V\):
\[
Z = \begin{bmatrix}
1 & 0 & 0 \\
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \\
0 & 0 & 1
\end{bmatrix}
\] The structure suggests that we are dealing with three distinct groups. Here’s how each block \(Z_i\) in the block diagonal matrix \(Z\) is formed and its role in the model:
Block \(Z_i\): \[
Z_i = \begin{bmatrix}
1 \\
1
\end{bmatrix}
\] This block corresponds to the group \(i\). In the second example where \(Z\) is:
This block corresponds to the first group. The first column of ones represents the intercept, and the second column represents the slope with respect to the covariate ‘age’. This group could represent a specific demographic or experimental condition.
Similar to the first, this block represents another group but with different age values. The structure again includes an intercept and a slope component, indicating a similar analysis but for a different subset of the population or a different experimental condition.
This block deals with yet another group, possibly older individuals based on the age values shown. The model structure for this group is consistent with the others, providing the ability to compare across groups while accounting for within-group variations.
Structure of V (cont.)
Given that we now know about the design matrix, we can go ahead and reformulate the stucture of \(V\) base on the design matrix. Please again assume that we are only dealing with intercept here so our design matrix looks like
\[
Z_i = \begin{bmatrix}
1 \\
1
\end{bmatrix}
\] If you remember the stucutre of \(V_i=\sigma^2 (\mathbf{I} + \frac{\sigma_d^2}{\sigma^2} \mathbf{11'})\).
If \(Z_i\) is only a column matrix of \(1\) then \(Z_iZ^{T}_{i}=\mathbf{11'}\). Let’s define matrix \(D\) as a block diagonal matrix where each block, \(D_i\), represents the variance components associated with the intercepts and possibly slopes for each group. Given the structure of \(V_i = \sigma^2 (\mathbf{I} + \frac{\sigma_d^2}{\sigma^2} \mathbf{11'})\), and assuming \(Z_i\) is structured to capture different types of effects (like intercept and slope as previously mentioned), the form of \(D\) and each \(D_i\) needs to reflect the appropriate variance scaling for these effects.
The matrix \(D\) is structured as:
\[
D = \begin{bmatrix}
D_1 & 0 & \cdots & 0 \\
0 & D_2 & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & D_N
\end{bmatrix}
\] where each block \(D_i\) is specific to a group and contains the variance components for the intercept and slope within that group. Assuming a simple case where each group has one intercept each \(Z_i\) block consists of one columns for intercept.
If we had intercept and slope, each \(D_i\) could be represented as a 2x2 matrix, because each \(Z_i\) block consists of two columns (one for intercepts and one for slopes).
Give \(D\) and \(Z_i\) we can now write \(V_i=\sigma^2 (\mathbf{I} + \frac{\sigma_d^2}{\sigma^2} \mathbf{11'})\) as
\[
V_i=\sigma^2 (\mathbf{I} + Z_iDZ_i^T)
\] The complete matrix form of \(V\) can be written as
\[
V=\sigma^2 (\mathbf{I} + ZDZ^T)
\]
Estimation of parameters
Given everything we have said so far, we now have complete ingredients to perform GLS. This includes our response variable \(y\), design matrix for the effect of interest \(X\) (fixed effect), a design matrix for grouping structure in the data \(Z\) and variance covariance matrix \(D\) which encodes \(\sigma^2\) (residual variance) and \(\sigma_d^2\) (variance of the grouping structure) which gives us \(V=\sigma^2 (\mathbf{I} + ZDZ^T)\).
What we have assumed so far is that we know \(V\) but in reality \(V\) is unknown. Since \(V\) is from using \(\sigma^2\) and \(\frac{\sigma_d^2}{\sigma^2}\), we need to estimate these two which we are going to denote as \(\theta=[\sigma^2,\frac{\sigma_d^2}{\sigma^2}]=[\sigma^2,\lambda]\).
To begin, in order to find the parameters for our model, we employ Maximum Likelihood Estimation (MLE). The goal is to estimate the \(\theta\) that best fit our model to the observed data.
The GLS model assumes that the response variable \(y\) is linearly dependent on multiple predictors, captured in matrix \(X\), with random errors \(\epsilon\) that are normally distributed but with a non-constant variance structure. This variance structure is modeled by \(\sigma^2 V\), where \(V\) depends on another matrix \(Z\) and a variance-covariance matrix \(D\). The model can be written as:
\[
y = X\beta + \epsilon, \quad \text{where} \quad \epsilon \sim N(0, \sigma^2 V).
\] Since \(\epsilon \sim N(0, \sigma^2 V)\), and \(\epsilon = y - X\beta\), we can say that \(y\), the response variable, is also normally distributed. This follows from the properties of the normal distribution where a linear transformation of a normally distributed variable is also normally distributed. Thus:
\[
y \sim N(X\beta, \sigma^2 V).
\] The probability density function for a multivariate normal distribution with mean \(\mu\) and covariance matrix \(\Sigma\) is given by:
\[
f(x) = \frac{1}{(2\pi)^{k/2} |\Sigma|^{1/2}} \exp\left(-\frac{1}{2} (x-\mu)^T \Sigma^{-1} (x-\mu)\right),
\] We substitute our model notation and it gives us
\[
\beta = (X^T V^{-1} X)^{-1} X^T V^{-1} y.
\] Ignore the constant \(-n \log(2\pi)\) as it does not depend on \(\beta\) or \(\theta\).
Substituting \(\tilde{\boldsymbol{\beta}}\) and acknowledging \(V\) as \(\tilde{\boldsymbol{V}}(\boldsymbol{\theta})\)gives: \[
-2\ell(\boldsymbol{\theta};\boldsymbol{Y}) = \log|\tilde{\boldsymbol{V}}(\boldsymbol{\theta})| + (Y-X\tilde{\boldsymbol{\beta}}(\boldsymbol{\theta}))^T \tilde{\boldsymbol{V}}(\boldsymbol{\theta})^{-1} (Y-X\tilde{\boldsymbol{\beta}}(\boldsymbol{\theta})).
\] Given this function we can go ahead and write a small piece of code to calculate this.
simulate_grouped_trend <-function(group_count =5, points_per_group =10, global_slope =-10, global_intercept =30, group_slope =2, noise_sd =50,noise_sd2=2) {set.seed(123) # Setting a seed for reproducibility# Initialize an empty data frame to store the simulated data data <-data.frame(x =numeric(), y =numeric())# Loop to create each groupfor (i in1:group_count) { x_start <-12+ (i -1) * (10/ group_count) # Stagger the start of x for each group x <-runif(points_per_group, min = x_start, max = x_start + (10/ group_count))# Apply a local positive trend within the group, but maintain the global negative trend local_intercept <- global_intercept + global_slope * (x_start + (10/ (2* group_count))) +rnorm(1, mean =0, sd = noise_sd) y <- local_intercept + group_slope[i] * (x - x_start) +rnorm(points_per_group, mean =0, sd = noise_sd2)# Combine this group with the overall dataset group_data <-data.frame(x = x, y = y,group=i) data <-rbind(data, group_data) }return(data)}# generate simulated datadata_int <-simulate_grouped_trend(group_count =4,points_per_group =10,global_slope =-2,global_intercept =100,group_slope =c(6,4,2,1),noise_sd =5,noise_sd2=2)# set group to factordata_int$group <-factor(data_int$group)# theta is [sigmal,lambda]# Design matrix of random effectZ <-model.matrix(~0+data_int$group)# Construct the model matrix 'X' for the fixed effect 'x' using data from 'data_int'.X <-model.matrix(~x, data=data_int)# get groups (random effects)groups <-unique(data_int$group)log1 <-function(theta) { D <-diag(x = theta[2],ncol =length(groups),nrow =length(groups)) I <-diag(1,nrow =nrow(X),ncol =nrow(X)) V<-theta[1]*(I+Z%*%D%*%t(Z)) Beta <-solve(t(X) %*%solve(V) %*% X) %*%t(X) %*%solve(V) %*% yreturn(c(log(det(V)) +t(y - X %*% Beta) %*%solve(V) %*% (y - X %*% Beta)))}theta<-optimization::optim_nm(fun = log1, k =2, start =c(1,1),maximum=FALSE, tol =0.0000000000001)$parcat("Residual = ",sqrt(theta[1])," group = ", sqrt(prod(theta)),"\n")
Residual = 2.40449 group = 16.61623
if we compare the results to that of lmer we see they are identical:
Groups Name Std.Dev.
group (Intercept) 16.6162
Residual 2.4045
Bias of MLE
While Maximum Likelihood Estimators are efficient and consistent under many conditions, they can be biased, particularly in estimating the variance in a model.
Consider a random sample \(y_1, y_2, \ldots, y_n\) from a normal distribution \(N(\mu, \sigma^2)\). We want to estimate the variance \(\sigma^2\) using MLE.
The probability density function for a single observation \(y_i\) given \(\sigma^2\) is:
To find the maximum likelihood estimator (MLE) for \(\sigma^2\), differentiate \(\ell(\sigma^2)\) with respect to \(\sigma^2\) and set this derivative to zero:
We now need to take the expectation of To find the expectation of \(\hat{\sigma}^2\). To do that we express it in terms of \(y_i - \mu\) and \(\overline{y} - \mu\)**
First, rewrite the squared term using the identity \(a - b = (a - c) + (c - b)\) where \(a = y_i\), \(b = \overline{y}\), and \(c = \mu\): \[
y_i - \overline{y} = (y_i - \mu) - (\overline{y} - \mu).
\] Thus, the squared term becomes:
Summing over all \(i\) from 1 to \(n\), we obtain: \[
\sum_{i=1}^n (y_i - \overline{y})^2 = \sum_{i=1}^n (y_i - \mu)^2 - 2 \sum_{i=1}^n (y_i - \mu)(\overline{y} - \mu) + \sum_{i=1}^n (\overline{y} - \mu)^2.
\] Since \(\overline{y} - \mu\) does not depend on \(i\), it can be factored out of the sums:
\[
\sum_{i=1}^n (y_i - \overline{y})^2 = \sum_{i=1}^n (y_i - \mu)^2 - 2(\overline{y} - \mu) \sum_{i=1}^n (y_i - \mu) + n(\overline{y} - \mu)^2.
\] Given that \(\sum_{i=1}^n (y_i - \mu) = n(\overline{y} - \mu)\), the middle term simplifies to:
\[
-2n(\overline{y} - \mu)^2,
\] and the equation becomes:
As said before MLE has a significant limitation: it tends to underestimate variance components due to its non-adjustment for the degrees of freedom consumed by the fixed effects. This underestimation arises because MLE maximizes a likelihood function using all available data, which inadvertently causes an overfitting of fixed effects, leading to biased and sometimes misleading estimates of variance.
This bias in MLE is known to result from too large a denominator in the variance formula, which does not account for the degrees of freedom used up by estimating the mean (fixed effects). Intuitively, this comes from how the sample mean is based on the same data, making the data points appear more clustered around the mean than they actually are, hence underestimating the true variability that a correct denominator would account for.
To address this issue, Restricted Maximum Likelihood (REML) was developed. REML refines the approach used by MLE by first fitting the fixed effects and then adjusting the likelihood function used to estimate variance components, specifically compensating for the degrees of freedom used in estimating the fixed effects. This adjustment ensures that the estimation of variance components is based on the correct amount of independent information.
A key aspect of REML is the process of “integrating out” the fixed effects. This approach involves focusing on the likelihood of the residuals after removing the influence of the fixed effects, rather than the likelihood of the entire dataset. By integrating out these effects, REML effectively separates the estimation of variance parameters from the estimation of the fixed effects, which can reduce bias in the variance estimates. The integration is achieved through a mathematical transformation where the fixed effects are marginalized over (integrated out), usually requiring the calculation of integrals over these parameters. This process results in a likelihood function that depends only on the random effects and the variance components, which REML then maximizes to obtain more accurate and less biased estimates.
Let’s have a look at our previous likelyhood function
Integrating out the fixed effects in REML involves focusing on the part of the log-likelihood that pertains only to the variance components, adjusting for the estimation of \(\beta\):
To rewrite this in the form of a completed square, it’s helpful to recognize the general form: \(\beta^T \mathbf{A} \beta - 2\beta^T \mathbf{b}\) Here, \(\mathbf{A} = \mathbf{X}^T V^{-1} \mathbf{X}\) and \(\mathbf{b} = \mathbf{X}^T V^{-1} \mathbf{Y}\).
We can rewrite it by completing the square in \(\beta\): \[
\beta^T \mathbf{X}^T V^{-1} \mathbf{X} \beta - 2\beta^T \mathbf{X}^T V^{-1} \mathbf{Y}
\]\[
= (\beta - \mathbf{A}^{-1}\mathbf{b})^T \mathbf{A} (\beta - \mathbf{A}^{-1}\mathbf{b}) - \mathbf{b}^T \mathbf{A}^{-1} \mathbf{b}
\] Where \(\mathbf{A}^{-1} = (\mathbf{X}^T V^{-1} \mathbf{X})^{-1}\).
From the earlier completion of the square, we know the integral’s argument can be expressed as: \[
(\beta - \mathbf{A} \mathbf{Y})^T \mathbf{X}^T V^{-1} \mathbf{X} (\beta - \mathbf{A} \mathbf{Y}) + \mathbf{Y}^T (V^{-1} - V^{-1} \mathbf{X} \mathbf{A}) \mathbf{Y}
\]
The integral of a Gaussian (quadratic form in the exponent) over \(\beta\) is: \[
e^{-\frac{1}{2} \mathbf{Y}^T (V^{-1} - V^{-1} \mathbf{X} \mathbf{A}) \mathbf{Y}} \cdot \int e^{-\frac{1}{2} (\beta - \mathbf{A} \mathbf{Y})^T \mathbf{X}^T V^{-1} \mathbf{X} (\beta - \mathbf{A} \mathbf{Y})} d\beta
\]
For the integral over \(\beta\), since it’s a Gaussian integral, it simplifies to: \[
(2\pi)^{\frac{k}{2}} \left|\mathbf{X}^T V^{-1} \mathbf{X}\right|^{-\frac{1}{2}}
\]
Where \(k\) is the number of parameters (dimension of \(\beta\)).
Rewriting the last part sing complete squares and simplifying (\(\mathbf{A} \mathbf{Y} = \tilde{\boldsymbol{\beta}}(\boldsymbol{\theta})\)):
\[
\mathbf{Y}^T V^{-1} \mathbf{Y} - \mathbf{Y}^T V^{-1} \mathbf{X} \mathbf{A} \mathbf{Y} = (\mathbf{Y} - \mathbf{X}\tilde{\boldsymbol{\beta(\boldsymbol{\theta})}})^T V^{-1} (\mathbf{Y} - \mathbf{X}\tilde{\boldsymbol{\beta(\boldsymbol{\theta})}})
\] Combining the rearranged terms, the full expression is: \[
-2\ell_{REML}(\boldsymbol{\theta};\boldsymbol{Y}) = \log |\tilde{\boldsymbol{V}}(\boldsymbol{\theta})| + \log |\boldsymbol{X}^T \tilde{\boldsymbol{V}}^{-1} \boldsymbol{X}| + (\boldsymbol{Y} - \boldsymbol{X}\tilde{\boldsymbol{\beta}}(\boldsymbol{\theta}))^T \tilde{\boldsymbol{V}}^{-1} (\boldsymbol{Y} - \boldsymbol{X}\tilde{\boldsymbol{\beta}}(\boldsymbol{\theta}))
\] This is our final equation for REML and can be implemented easily:
# theta is [sigmal,lambda]# Design matrix of random effectZ <-model.matrix(~0+data_int$group)# Construct the model matrix 'X' for the fixed effect 'x' using data from 'data_int'.X <-model.matrix(~x, data=data_int)# get groups (random effects)groups <-unique(data_int$group)log_reml <-function(theta) { D <-diag(x = theta[2],ncol =length(groups),nrow =length(groups)) I <-diag(1,nrow =nrow(X),ncol =nrow(X)) V<-theta[1]*(I+Z%*%D%*%t(Z)) Beta <-solve(t(X) %*%solve(V) %*% X) %*%t(X) %*%solve(V) %*% yreturn(c(log(det(V)) +log(det(t(X) %*%solve(V) %*% X))+t(y - X %*% Beta) %*%solve(V) %*% (y - X %*% Beta)))}theta<-optimization::optim_nm(fun = log_reml, k =2, start =c(1,1),maximum=FALSE, tol =0.0000000000001)$parcat("Residual = ",sqrt(theta[1])," group = ", sqrt(prod(theta)),"\n")
Groups Name Std.Dev.
group (Intercept) 19.4578
Residual 2.4355
Other methods of fitting
In practice, when dealing with this kind of models, we do not directly optimize the log-likelihood function due to its complexity, particularly when random effects are included. Instead, more tractable approaches such as the Expectation-Maximization (EM) algorithm, Newton-Raphson, and quasi-likelihood methods are commonly employed. These techniques facilitate the optimization process by breaking it down into simpler steps or by approximating the log-likelihood function. For instance, the EM algorithm efficiently handles missing data or latent variables by iteratively estimating expected values and maximizing the likelihood. Newton-Raphson and related methods, on the other hand, provide robust mechanisms for dealing with non-linear optimization through successive approximations. These methods are essential for ensuring convergence and computational feasibility in the analysis of mixed models.
Best Linear Unbiased Estimators (BLUE)
Now that we have estimated the components of \(V\), we can show that \(B\) is in fact Best Linear Unbiased Estimators (BLUE). This involves proving that the GLS estimator is both unbiased and has the smallest variance among all linear unbiased estimators.
Recall the GLS estimator is defined as: \[
\hat{\beta}_{GLS} = (X^T V^{-1} X)^{-1} X^T V^{-1} y
\] where \(V\) is the known covariance matrix of the errors \(e\) in the model \(y = X\beta + e\).
The model equation is: \[
y = X\beta + e
\] where \(e\) is the error term with \(E(e) = 0\) and \(Var(e) = \sigma^2 V\).
Plug the expression for \(y\) into the GLS estimator: \[
\hat{\beta}_{GLS} = (X^T V^{-1} X)^{-1} X^T V^{-1} (X\beta + e)
\] Break the expression into two parts by distributing \(X^T V^{-1}\): \[
\hat{\beta}_{GLS} = (X^T V^{-1} X)^{-1} X^T V^{-1} X\beta + (X^T V^{-1} X)^{-1} X^T V^{-1} e
\] Notice that \(X^T V^{-1} X\) and \((X^T V^{-1} X)^{-1} X^T V^{-1} X\) simplify as follows: \[
(X^T V^{-1} X)^{-1} X^T V^{-1} X = I
\] where \(I\) is the identity matrix, thus: \[
\hat{\beta}_{GLS} = \beta + (X^T V^{-1} X)^{-1} X^T V^{-1} e
\] To show unbiasedness, we take the expectation of \(\hat{\beta}_{GLS}\): \[
E(\hat{\beta}_{GLS}) = E(\beta + (X^T V^{-1} X)^{-1} X^T V^{-1} e)
\]\[
E(\hat{\beta}_{GLS}) = \beta + E((X^T V^{-1} X)^{-1} X^T V^{-1} e)
\] Since \(E(e) = 0\): \[
E((X^T V^{-1} X)^{-1} X^T V^{-1} e) = (X^T V^{-1} X)^{-1} X^T V^{-1} E(e) = 0
\] Therefore: \[
E(\hat{\beta}_{GLS}) = \beta
\]
The expectation of the GLS estimator is equal to the true parameter vector \(\beta\), so \(\hat{\beta}_{GLS}\) is an unbiased estimator of \(\beta\). That means covariance structure \(V\) of the errors do not introduce any bias into the estimator.
Lastly we need to show that variance of the GLS estimator \(\beta_{GLS}\) is lower than or equal to the variance of any other linear unbiased estimator.
Let’s first derive the variance of \(\beta_{GLS}\)
Recall that \[
\hat{\beta}_{GLS} = (X^T V^{-1} X)^{-1} X^T V^{-1} y
\]
Since \(y = X\beta + e\) and the errors \(e\) have covariance \(\sigma^2 V\), the variance of \(y\) is: \[
Var(y) = \sigma^2 V
\] Give the linear transformation rule for variance (\(Var(Ay) = A Var(y) A^T\)), which states that for any linear transformation \[
Var(\hat{\beta}_{GLS}) = Var\left((X^T V^{-1} X)^{-1} X^T V^{-1} y\right)
\]\[
= (X^T V^{-1} X)^{-1} X^T V^{-1} Var(y) V^{-1} X (X^T V^{-1} X)^{-1}
\]\[
= (X^T V^{-1} X)^{-1} X^T V^{-1} (\sigma^2 V) V^{-1} X (X^T V^{-1} X)^{-1}
\] Simplifying: \[
= \sigma^2 (X^T V^{-1} X)^{-1} X^T V^{-1} V V^{-1} X (X^T V^{-1} X)^{-1} = \sigma^2 (X^T V^{-1} X)^{-1} (X^T V^{-1} X) (X^T V^{-1} X)^{-1}
\]\[
= \sigma^2 (X^T V^{-1} X)^{-1}
\]
The variance of the GLS estimator \(\hat{\beta}_{GLS} = Var(\hat{\beta}_{GLS}) = \sigma^2 (X^T V^{-1} X)^{-1}\)
Any other linear unbiased estimator \(\hat{\beta}_L\) can be expressed as: \[
\hat{\beta}_L = CY
\] where \(C\) must satisfy \(CX = I\) for unbiasedness. Specifically, we can define \(C\) as: \[
C = (X^TV^{-1}X)^{-1}X^TV^{-1} + M
\] where \(M\) is a matrix such that \(MX = 0\). This ensures that \(\hat{\beta}_L\) is unbiased: \[
E[\hat{\beta}_L] = \beta + MXE[\beta] = \beta
\] since \(E[y] = X\beta\).
Given the model \(y = X\beta + e\) with \(Var(e) = \sigma^2 V\), the variance of \(y\) is \(\sigma^2 V\), and hence: \[
Var(\hat{\beta}_L) = C \sigma^2 V C^T
\]
Substituting \(C\) into the variance formula, we get: \[
Var(\hat{\beta}_L) = \left((X^TV^{-1}X)^{-1}X^TV^{-1} + M\right) \sigma^2 V \left((X^TV^{-1}X)^{-1}X^TV^{-1} + M\right)^T
\] Expanding and using \(MX = 0\), we have: \[
Var(\hat{\beta}_L) = \sigma^2 \left((X^TV^{-1}X)^{-1} + MVM^T\right)
\]
Since \(\sigma^2 (X^T V^{-1} X)^{-1}=Var(\hat{\beta}_{GLS})\) then \(Var(\hat{\beta}_L) = Var(\hat{\beta}_{GLS}) + \sigma^2 MVM^T\)
\(MVM^T\) is a positive semi-definite matrix since \(V\) is positive definite (or semi-definite if \(V\) is not strictly positive). This implies \(\sigma^2 MVM^T \geq 0\) which gives us \(Var(\hat{\beta}_L) \geq Var(\hat{\beta}_{GLS})\).
This shows that any deviation from the GLS estimator in the form of an additional matrix \(M\) results in an increase in variance. Therefore, the GLS estimator \(\hat{\beta}_{GLS}\) is the Best Linear Unbiased Estimator (BLUE) for models where the errors have a covariance structure described by \(\sigma^2 V\).
Random Effects
I want to briefly review the components we’ve discussed so far before proceeding with random effects
Design Matrix, \(Z\): This matrix is called the design matrix for the random effect and encodes how each observation in our dataset is related to other observations within the same group or category. It effectively organizes our data according to predetermined groupings.
Covariance Matrix, \(D\): \(D\) is the covariance matrix associated with the groupings defined by \(Z\). It quantifies the variance within each group as well as the covariance between groups.
Error Terms: Often denoted as \(\sigma^2\), this represents the variance of the error terms in our models. It captures the amount of variability in our observations that isn’t explained by the model.
What we tried to model so far is that we believe there is certain grouping in the data which we encoded by by \(Z\). What we believe is that for one or more of our primary effects just as intercept, slope etc there exist variabilities that are specific to these groups and not fully captured by these primary effects alone. This variability, which may come from unique characteristics or influences within each group. We modeled this variability using \(D\). If we suspected that only a single effect such as intercept was affected by groups, \(D\) will be diagonal, meaning that it will have a single value repeating on its diagonal element. If we suspect 2 or more effects are random, then \(D\) is block diagona. Each block’s size corresponds to the number of effects considered to be random within a group, effectively capturing the covariance between these effects across different groupings.
I guess you realized that our aim has never been to estimate the exact influence of each single group on the effects but rather to say that they are from a distribution that captures the inherent variability among the groups. If we have thousands of data points, we might as well consider estimating directly each group’s effect; however, such an approach can quickly become unwieldy and prone to overfitting, especially in cases where groups are many but each group has few observations. By using a model that incorporates random effects, we effectively balance the need for specificity in modeling group influences against the practical constraints of model complexity and the risk of fitting noise rather than signal. Also have this in mind that, we might not be interested in the effects of each group but rather just quantifying the influence collectively would be sufficient.
Having said that, we know that these groupings affect the observed data, yet unlike fixed effects, random effects are not directly observable. They represent underlying influences or variables that affect the outcome but are not included as direct measurements in the data. For example, in a study on student performance across schools, random effects might include inherent school qualities like teaching methods or school climate, which are not directly measured but still influence student outcomes. Despite being unseen, we can predict these random effects. This is different to directly estimating a parameter in that prediction focuses on the likely values of random variables for specific instances or groups, given the observed data and the model structure. We are going to denote these prediction as \(u\) here.
We we said is that \(u\) is coming from a distribution \(D\) as covariance parameter and mean of zero. so \(u \sim N(0, \sigma^2D)\) and we also said that our residuals are distributed as \(e \sim N(0, \sigma^2)\).
The errors \(e\) and the random effects \(u\) are assumed independent.
Given the assumptions and linearity, the observations \(y\) are also normally distributed with: - Mean: \(E(y) = X\beta\) (since \(E(u) = 0\) and \(E(e) = 0\)) - Covariance: \(Var(y) = Z\sigma^2DZ^T + \sigma^2I\)
Please note that this is because our total variation is variation of \(Zu\) and \(e\) so \(Var(Zu) = ZDZ^T\) and \(Var(e) = \sigma^2\), utilizing the independence of \(u\) and \(e\).
Therefore \(y \sim N(X\beta, \sigma^2(I+ZDZ^T))\)
When we have a pair of random variables \(X\) and \(Y\), and we know the outcome of \(Y\), the conditional expectation \(E(X | Y)\) serves as the best predictor of \(X\) based on \(Y\), in the mean squared error sense. This is because it minimizes the expected squared difference between the predicted values and the actual values of \(X\), compared to any other function of \(Y\).
The conditional expectation of \(X\) given \(Y\) in a bivariate normal distribution can be expressed as:
To apply conditional expectation, recognize that \(u\) and \(y\) have a joint normal distribution. We can reformulate conditional expectation in a form suitable for our model:
\[
E(u | y) = E(u) + Cov(u, y)Var(y)^{-1}(y - E(y))
\] - \(E(u) = 0\) and \(E(y) = X\beta\) - \(Cov(u, y)\) needs to be calculated: \[Cov(u, y) = Cov(u, Zu + e)\]\[= Cov(u, Zu) + Cov(u, e)\]\[= \sigma^2DZ^T + 0\]\[= \sigma^2DZ^T\] The last equality is because \(Cov(u, e) = 0\) due to independence and \(Cov(u, Zu) = \sigma^2DZ^T\) because
Given that \(E[u] = 0\) (since \(u\) is assumed to have mean zero), the expression simplifies to: \[
\text{Cov}(u, Zu) = E[u(Zu)^T]
\]
\[
E[u(Zu)^T] = E[u(u^T Z^T)]
\] Here, \(u^T Z^T\) is simply a rearrangement of the multiplication. T
The inner operation \(u(u^T Z^T)\) results in a matrix where each element is a product of elements from \(u\) and \(u^T\), transformed by \(Z^T\).
\[
E[uu^T] = \sigma^2D
\]
So, applying \(Z^T\) to each element effectively results in:
\[
E[u(u^T Z^T)] = E[uu^T]Z^T = \sigma^2DZ^T
\]
Using the formula for conditional expectation in multivariate normal distributions: \[E(u | y) = 0 + \sigma^2DZ^T(Z\sigma^2DZ^T + \sigma^2)^{-1}(y - X\beta)\]\[= \sigma^2DZ^T V^{-1} (y - X\beta)\] where \(V = Z\sigma^2DZ^T + \sigma^2\) is the covariance matrix of \(y\).
The final predictor \(\hat{u}\) is: \[\hat{u} = \sigma^2DZ^T V^{-1} (y - X\beta)\]
Let’s give this a try to see if it gives us correct results:
# Design matrix of random effectZ <-model.matrix(~0+data_int$group)# Construct the model matrix 'X' for the fixed effect 'x' using data from 'data_int'.X <-model.matrix(~x, data=data_int)# get groups (random effects)groups <-unique(data_int$group)log_reml <-function(theta) { D <-diag(x = theta[2],ncol =length(groups),nrow =length(groups)) I <-diag(1,nrow =nrow(X),ncol =nrow(X)) V<-theta[1]*(I+Z%*%D%*%t(Z)) Beta <-solve(t(X) %*%solve(V) %*% X) %*%t(X) %*%solve(V) %*% yreturn(c(log(det(V)) +log(det(t(X) %*%solve(V) %*% X))+t(y - X %*% Beta) %*%solve(V) %*% (y - X %*% Beta)))}theta<-optimization::optim_nm(fun = log_reml, k =2, start =c(1,1),maximum=FALSE, tol =0.0000000000001)$parD <-diag(x = theta[2],ncol =length(groups),nrow =length(groups))I <-diag(1,nrow =nrow(X),ncol =nrow(X))V<-theta[1]*(I+Z%*%D%*%t(Z))Beta <-solve(t(X) %*%solve(V) %*% X) %*%t(X) %*%solve(V) %*% yu <- theta[1]*D%*%t(Z)%*%solve(V)%*%(y-X%*%Beta)print(u)
$group
(Intercept)
1 26.705636
2 1.337016
3 -11.314930
4 -16.727722
with conditional variances for "group"
We get identical results! These values are also called to be Best Linear Unbiased Prediction (BLUP) because Unbiasedness (\(E(E(u | y)) = E(u) = 0\)) and minization of the variance of the prediction error \(E[(u - \hat{u})^2]\) among all linear unbiased predictors. We are not going to prove them here as we did similar analysis up there fore BLUEs.
Final mixed model form
So all together, we now know that each observation in our data can be described by our fixed effects and predicted random effects plus some random noise.
Putting all together we have
\[y = X\beta + Zu + e\]
This describes our data model, where:
\(y\) is the vector of observed data.
\(\beta\) represents fixed effects, which may or may not be of interest for the derivation.
\(u\) represents the random effects we wish to predict.
\(e\) is the error term.
\(X\) and \(Z\) are known design matrices.
We also assume: - \(u \sim N(0, \sigma^2D)\), where \(D\) is the covariance matrix of the random effects. - \(e \sim N(0, \sigma^2)\), where \(\sigma^2\) is the covariance matrix of the residuals. - \(u\) and \(e\) are independent.
This is the final form of the mixed model which we derived starting from OLS.
p-value for mixed models (Satterthwaite approximation)
This should be clear by now that mixed models are inherently more complex than OLS. This complexity goes also to statistical testing. In this section, I want to write a bit about statistical testing both from the classical perspective but also from linear models and mixed models. Again we are not going to go through all details but just demonstrate some of the key concepts.
How rare is this value?!
Let’s assume we have a specific value from our dataset that we’re curious about its rarity. The only way to accurately assess how rare this value is involves understanding where it falls within an overall distribution of data. This compares the value against a bunch of expected values. Ff it deviates significantly from what’s typical, then we can consider it rare. To do this, we first need to define the distribution that best describes our dataset. A common assumption to make about a dataset is that it follows a normal distribution. Many natural phenomena and human-made processes tend to distribute their values in a way that can be symmetrically modeled around a central value, with fewer occurrences appearing as one moves further away from this central point.
If we assume that our data follows a normal distribution, we can use its mathematical properties to check the rarity of specific observations within our dataset.
In probability, the “density” of a value in a continuous distribution refers to the relative likelihood of this value occurring. For a normal distribution values closer to the mean are more densely packed and so more likely to occur. As we move away from the mean, the density decreases, indicating that these values are less likely and rarer.
The density function doesn’t give the probability of the event occurring at exactly a specific point (which in continuous distributions is technically zero), but rather it helps us understand how dense the distribution is around that point, which is indicative of the probability of observing values in a small interval around that point.
The probability density function for a normal distribution is given by:
Here: - \(x\) is the value for which we are calculating the probability density. - \(\mu\) is the mean of the distribution. - \(\sigma\) is the standard deviation, which measures the dispersion of the data around the mean. - \(\sigma^2\) is the variance.
To determine how rare or unusual a particular value \(x\) is within a normal distribution, we need to calculate the probability of observing \(x\) or a value more extreme (larger or smaller, depending on the context). This is typically done using the cumulative distribution function (CDF), which gives the probability that a normally distributed random variable is less than or equal to a certain value.
CDF is represented by the integral of the probability density function from negative infinity to $ x $. Mathematically, it’s expressed as:
For instance, if we want to calculate the probability of observing a value less than or equal to 60 from a normal distribution with a mean of 50 and a standard deviation of 10:
# Parametersmu <-50sigma <-10# Value to calculate the cumulative probability forx <-60# Calculate the probabilityprobability <-pnorm(x, mean = mu, sd = sigma)print(probability)
[1] 0.8413447
I guess you realized that we have an infinite number of normal distributions defined by particular parameters (\(\mu\) and \(\sigma\)). However, it is often nice to have a standard one from which we can derive a table of probabilities. This distribution is called the standard normal distribution.
Standard normal distribution
The standard normal distribution is a specific instance of the normal distribution where the mean (\(\mu\)) is 0 and the standard deviation (\(\sigma\)) is 1. This standardization simplifies many statistical methods and allows us to use a single, universally applicable table (commonly called the Z-table) for finding probabilities
To convert any normal distribution to the standard normal distribution, values are transformed into what are known as Z-scores. This transformation process is called standardization. A Z-score tells us how many standard deviations away a point is from the mean of the distribution.
The formula to calculate the Z-score of a value \(x\) is:
\[Z = \frac{(x - \mu)}{\sigma}\]
Where:
\(x\) is the value from the original distribution.
\(\mu\) is the mean of the original distribution.
\(\sigma\) is the standard deviation of the original distribution.
Let’s consider an example where we calculate the Z-scores:
# Sample data valuesdata_values <-c(40, 55, 60, 45, 70)# Mean and standard deviation of the datasetmu <-50sigma <-10# Calculate Z-scoresz_scores <- (data_values - mu) / sigma# Output Z-scoresprint(z_scores)
[1] -1.0 0.5 1.0 -0.5 2.0
We can now use a standard normal distribution for finding probabilities.
For any random variable we can write the transformation as
\[Z = \frac{(X - \mu)}{\sigma}\]
Now suppose that we went and collected a few samples and measured its mean \(\bar{X}\) and we want to check how likely is that to get a value larger or smaller than \(\bar{X}\). We can do a \(z\) transformation but with a small difference.
There is however a small difference here. Eventhough the sample can be used to calculate unbiased estimates of the population property, the sample estimate will not be perfect. The standard deviation of the sampling distribution is called the standard error or \(SE\). If each \(X_i\) is normally distributed with mean \(\mu\) (mean of population) and standard deviation \(\sigma\), then:
Expected Value: \(E[\overline{X}] = \mu\)
Variance: Since \(X_i\) are independent, the variance of the sum is the sum of the variances: \(Var(\overline{X}) = Var\left(\frac{1}{n} \sum_{i=1}^n X_i\right) = \frac{1}{n^2} \sum_{i=1}^n Var(X_i) = \frac{1}{n^2} \cdot n \sigma^2 = \frac{\sigma^2}{n}\)
The standard error of the mean is:
\(SEM = \frac{\sigma}{\sqrt{n}}\)
So we change the definiton of \(Z\) for sample mean to
\[Z = \frac{(\bar{X} - \mu)}{\frac{\sigma}{\sqrt{n}}}\] Which can be used to derive the probability. However, there is a challenge! So far, we have assumed that we know the variance of the population. In many practical situations \(\sigma\) is not known and must be estimated from the sample data we call it \(SE\).
\[
SE = \frac{s}{\sqrt{n}}
\]
Here, \(s\) is the sample standard deviation, and \(n\) is the sample size. The standard error provides a measure of how much error is expected in the estimate of the mean. As the sample size increases, the standard error decreases, indicating a more accurate estimate of the population mean.
Our standarized value now becomes
\[
\frac{\bar{X} - \mu}{SE}
\]
There is again a small little question here: Is this actually normal distribution?
Let’s see if we can write \(\frac{\bar{X} - \mu}{SE}\) in terms of distributions that we already know such as \(Z\).
We know that
\[
\frac{\bar{X} - \mu}{SE}=\frac{\overline{X} - \mu}{S / \sqrt{n}}
\] Where \(S\) is the standard deviation of samples.
Recall that \(Z = \frac{\overline{X} - \mu}{\sigma/\sqrt{n}}\).
So we can write
\[
\overline{X} - \mu = Z \cdot \frac{\sigma}{\sqrt{n}}
\]
Plugging this into the expression \(\frac{\overline{X} - \mu}{S / \sqrt{n}}\), we have:
Now we should work our way around \(\frac{\sigma}{S}\) and write it in a form that has know distribution.
Remember that sample mean \(\overline{X}\) and sample variance \(S^2\) are defined as follows: \[
\overline{X} = \frac{1}{n} \sum_{i=1}^1 X_i
\]\[
S^2 = \frac{1}{n-1} \sum_{i=1}^n (X_i - \overline{X})^2
\]
Now consider the sum of squared deviations from the mean: \[
\sum_{i=1}^n (X_i - \overline{X})^2 = \sum_{i=1}^n \left[ (X_i - \mu) - (\overline{X} - \mu) \right]^2
\] Using the property of variance and the independence of \(X_i\), we know: \[
\sum_{i=1}^n (X_i - \overline{X})^2 = \sum_{i=1}^n (X_i - \mu)^2 - n(\overline{X} - \mu)^2
\]
Since \(X_i\) are i.i.d. \(N(\mu, \sigma^2)\), \((X_i - \mu)/\sigma\) are i.i.d. \(N(0, 1)\), we know that: \[
\sum_{i=1}^n \left( \frac{X_i - \mu}{\sigma} \right)^2 \sim \chi^2_n
\]
However, we are interested in \(\sum_{i=1}^n (X_i - \overline{X})^2\). Note that \(\overline{X}\) itself is \(N(\mu, \sigma^2/n)\).
By Cochran’s theorem, the sum of squared deviations can be split into independent parts: \[
\sum_{i=1}^n (X_i - \mu)^2 = \sum_{i=1}^n (X_i - \overline{X})^2 + n(\overline{X} - \mu)^2
\] where \(\sum_{i=1}^n (X_i - \overline{X})^2\) and \(n(\overline{X} - \mu)^2\) are independent.
Now, \(\sum_{i=1}^n (X_i - \overline{X})^2\) follows a chi-squared distribution with \(n-1\) degrees of freedom: \[
\sum_{i=1}^n (X_i - \overline{X})^2 \sim \sigma^2 \chi^2_{n-1}
\]
We have: \[
S^2 = \frac{1}{n-1} \sum_{i=1}^n (X_i - \overline{X})^2
\] So, we can write: \[
(n-1)S^2 = \sum_{i=1}^n (X_i - \overline{X})^2
\]
We know that a random variable \(Z\)) that is standard normally distributed, denoted \(Z \sim N(0, 1)\), has a probability density function (PDF): \[
f_Z(z) = \frac{1}{\sqrt{2\pi}} e^{-\frac{z^2}{2}}
\]
Also a chi-squared distribution with \(d\) degrees of freedom, denoted \(U \sim \chi^2_d\), can be expressed as the sum of squares of \(d\) independent standard normal variables. Its PDF is given by:
\[
T = \frac{Z}{\sqrt{\frac{U}{d}}} = \frac{Z}{\sqrt{V}}
\]
where \(V = \frac{U}{d}\).
We now have to find PDF of \(T\) which a joint PDF if weassume that \(Z\) and \(V\) are independent. The joint PDF of \(Z\) and \(V\), \(f_{Z,V}(z,v)\), is the product of their marginal PDFs:
Directly working with \(f_{Z,V}(z, v)\) to find the PDF of \(T\) involves solving an integral where \(T\) is a function of both \(Z\) and \(V\). Instead we are going to write things in terms of \(T\) using change variables method.
Let’s start with
\[
Z = T\sqrt{W}, \quad V = W
\]
where \(W\) is just a placeholder to help in calculation. This is an easier form to work with but the problem is when working with transformation of random variables, the volume that the probability density covers can change. In order to conserve the total probability between the orignal and the transformed space we need to derive how much we have to strech or compress the transformed space. determinant of Jacobian gives us a way to calculate this scaling factor.
Given:
\[
Z = T\sqrt{W}, \quad V = W
\]
To find the Jacobian determinant, we compute the partial derivatives:
\[
\frac{Z}{\sqrt{\frac{U}{d}}} \sim t_d
\] with \(d\) degrees of freedom and \(Z \sim N(0,1)\) and \(U \sim chi^2_d\).
t-statistics for OLS
Consider a linear model given by: \[
Y = X\beta + \epsilon
\] In order to do a t-statistics, we need to first create a hypothesis. To create such a hypothesis we need a linear contrast that is a specific linear combination of the estimated regression coefficients. It’s typically represented as \(c'\beta\)
where:
\(c\) is a known \(p \times 1\) vector, specifying the coefficients for the linear combination.
\(\beta\) is the \(p \times 1\) vector of true regression coefficients.
The purpose of \(c\) is to focus on specific hypotheses about combinations of the parameters \(\beta\). For example, if we are interested in testing whether the sum of two coefficients is zero or some other value, \(c\) would be constructed accordingly to weight these coefficients. Similarly, if we have a bunch coefficients and we want to test whether one of them is different from zero or not we can construct a \(p \times 1\) vector which has all the elements zero except for the coefficient that we want to test.
\(c'\beta\) in fact gives us the numerator of the t-statistics. So we have
\[
t=\frac{c'\beta}{SE}
\] We still need to figure out what \(SE\) is.
Recall that \(SE\) is the standard error of \(c'\beta\). So we need to derive the variance of the estimated regression coefficients (\(\hat{\beta}\)). Although we have done that before, let’s go through it one more time.
The variance of a linear transformation \(A\) of a random vector \(b\) (where \(A\) is a matrix and \(b\) is a vector of random variables with variance-covariance matrix \(\Sigma\)) is given by: \[\text{Var}(Ab) = A \Sigma A'\] Applying this to \(\hat{\beta}\): \[\hat{\beta} = (X'X)^{-1}X'Y\]\[Y = X\beta + \epsilon\]\[\text{Var}(\hat{\beta}) = \text{Var}((X'X)^{-1}X'Y)\] Since \(Y = X\beta + \epsilon\) and \(X\beta\) is non-random (deterministic), the variance part comes only from \(\epsilon\): \[\text{Var}(\hat{\beta}) = \text{Var}((X'X)^{-1}X'(X\beta + \epsilon))\]\[\text{Var}(\hat{\beta}) = \text{Var}((X'X)^{-1}X'\epsilon)\] Given \(\text{Var}(\epsilon) = \sigma^2 I\): \[\text{Var}(\hat{\beta}) = (X'X)^{-1}X'(\sigma^2 I)X(X'X)^{-1}\]\[\text{Var}(\hat{\beta}) = \sigma^2 (X'X)^{-1}X'IX(X'X)^{-1}\]\[\text{Var}(\hat{\beta}) = \sigma^2 (X'X)^{-1}\]
The unbiased estimator of \(\sigma^2\) (variance of the errors) is given by the Residual Sum of Squares (RSS) divided by the degrees of freedom, which is typically the number of observations minus the number of parameters estimated (including intercept). If \(n\) is the number of observations and \(p\) is the number of parameters (including the intercept), the degrees of freedom are \(n - p\): \[\hat{\sigma}^2 = \frac{\text{RSS}}{n - p}\]
calculate_t_statistic <-function(X, Y, c) {# Calculate the OLS estimates for beta beta_hat <-solve(t(X) %*% X) %*%t(X) %*% Y# Calculate RSS Y_hat <- X %*% beta_hat rss <-sum((Y - Y_hat)^2)# Degrees of freedom n <-nrow(X) # Number of observations p <-ncol(X) # Number of parameters df <- n - p# Variance estimate sigma_squared_hat <- rss / df# Calculating c'beta c_beta_hat <-as.numeric(c %*% beta_hat)# Calculating the variance of c'beta_hat var_c_beta_hat <- sigma_squared_hat * (c %*%solve(t(X) %*% X) %*% c)# t-statistic t_statistic <- c_beta_hat /sqrt(var_c_beta_hat)return(t_statistic)}# Construct the model matrix 'X' for the fixed effect 'x' using data from 'data_int'.X <-model.matrix(~x, data=data_int)y<-data_int$yprint(data.frame(t=calculate_t_statistic(X = X,Y = y,c =c(0,1)),df=nrow(X)-ncol(X),pvalue=2*pt(abs(calculate_t_statistic(X = X,Y = y,c =c(0,1))),df=nrow(X)-ncol(X),lower.tail =FALSE)))
t df pvalue
1 -6.932677 38 3.033548e-08
Compare to lm function
print(summary(lm(y~0+X)))
Call:
lm(formula = y ~ 0 + X)
Residuals:
Min 1Q Median 3Q Max
-14.1384 -4.3018 0.0277 4.2264 17.5140
Coefficients:
Estimate Std. Error t value Pr(>|t|)
X(Intercept) 120.1292 6.8039 17.656 < 2e-16 ***
Xx -2.7184 0.3921 -6.933 3.03e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.238 on 38 degrees of freedom
Multiple R-squared: 0.991, Adjusted R-squared: 0.9905
F-statistic: 2094 on 2 and 38 DF, p-value: < 2.2e-16
degrees of freedom of GLS
In mixed models, determining the degrees of freedom (df) is complex due to the presence of both fixed and random effects. Unlike simple linear models where df is straightforward (number of observations minus number of parameters), mixed models must account for the hierarchical structure of the data and correlations within random effects. Methods like Satterthwaite and Kenward-Roger approximations are often used to estimate df. We are again going to just use the definition of GLS and not \(y = X\beta + Zb + \epsilon\) and demonstrate how Satterthwaite approximation works.
We know from the very first sections the estimated fixed effects \(\hat{\beta}\) are given by:
\[
\hat{\beta} = (X'V^{-1}X)^{-1}X'V^{-1}y
\] where \(V = ZDZ' + \sigma^2\) is the variance-covariance matrix of \(y\).
If you remember we also proved that the variance of the \(\beta\) is \((X'V^{-1}X)^{-1}\).
But what we are interested is the test of coeffcient \(c'\hat{\beta}\). From the OLS part above we can show that
\[
\text{Var}(c'\hat{\beta}) = c' \text{Var}(\hat{\beta}) c = c' (X'V^{-1}X)^{-1} c
\]
The test statistic for testing \(c'\beta = 0\) is constructed as: \[
T = \frac{c'\hat{\beta}}{\sqrt{\text{Var}(c'\hat{\beta})}}
\]
Substitute the variance expression:
\[
\text{Var}(c'\hat{\beta}) = c' (X'V^{-1}X)^{-1} c
\]
So, the test statistic becomes: \[
T = \frac{c'\hat{\beta}}{\sqrt{c' (X'V^{-1}X)^{-1} c}}
\]
This test statistic follows a t-distribution with degrees of freedom that can be approximated using the Satterthwaite approximation. However unlink OLS we don’t want to use \(n-p\) as degrees of freedom. We need to estimate it.
If you remember from the definition of T-stats we derived \(\sqrt{c' (X'V^{-1}X)^{-1} c} \sim ch^2_d\) (we still don’t know \(d\)).
However, just earlier we proved that:
\[
\frac{(n-1)S^2}{\sigma^2} \sim \chi^2_{n-1}
\] Let’s call the DF here (\(n-1\)) is \(d\) so we have
\[
\frac{(d)S^2}{\sigma^2} \sim \chi^2_{d}
\] We know the definition \(S^2=c' (X'V^{-1}X)^{-1} c\). But \(\sigma^2\) is true but unknow variance of the population. Let’s call this \(\sigma^2=c' (X'V_p^{-1}X)^{-1} c\)
We can now say that \(S^2 \approx \frac{\sigma^2}{d} \chi^2_{d}\). Given this we are going to match the first two momnets of \(S^2\) and \(\frac{\sigma^2}{d} \chi^2_{d}\) to see if we can derive \(d\)
Let’s start with expectation (first moment) \[
\mathbb{E}(S^2) = \mathbb{E}\left(\frac{\sigma^2}{d} \chi^2_{d}\right) = \frac{\sigma^2}{d} \mathbb{E}(\chi^2_{d}) = \frac{\sigma^2}{d} d = \sigma^2
\] Unfortunately \(d\) did not stay in this moment. Let’s go to the second moment (variance).
This is much better. We have \(d\) left in the formula. So we have
\[
\text{Var}(S^2) = \frac{2\sigma^4}{d}
\]
We can write:
\[
d=\frac{2\sigma^4}{Var(S^2)}
\] We can estimate \(\sigma^2\) as \(c' (X'V^{-1}X)^{-1} c\) which is \(S^2\). so we can write
\[
d=\frac{2(c' (X'V^{-1}X)^{-1} c)^2}{Var(c' (X'V^{-1}X)^{-1} c)}
\] The numerator is simple to calculate but denominator is more complex.
Remember that \(c' (X'V^{-1}X)^{-1} c\) involes estimating \(V\) which itself is a function of a parameter \(\theta\). To fix this we are going to use the delta method. The delta method can be used to approximate the variance of a function of a random variable.
If \(g(\theta)\) is a differentiable function of \(\theta\), and \(\theta\) has an approximate normal distribution \(N(\hat{\theta}, \Sigma)\) where \(\Sigma\) is the covariance matrix of \(\theta\)), the variance of \(g(\theta)\) can be approximated as:
\[
\text{Var}(g(\theta)) \approx \nabla g(\hat{\theta})' \Sigma \nabla g(\hat{\theta})
\] where \(\nabla g(\hat{\theta})\) is the gradient (vector of first partial derivatives) of \(g\) evaluated at $ $ and \(g(\theta) = c' (X'V^{-1}X)^{-1} c\).
We need to compute \(\nabla g(\theta)\), the gradient of \(g\) with respect to \(\theta\). This involves differentiating \(c' (X'V^{-1}X)^{-1} c\) with respect to each element of \(\theta\). We are just going to estimate this here but in practice this can be found using Jacobian. and \(\Sigma\) is going to be estimated using the Hessian of the log-likelihood. Let’s see how we can implement this
library(numDeriv)simulate_grouped_trend <-function(group_count =5, points_per_group =10, global_slope =-10, global_intercept =30, group_slope =2, noise_sd =50,noise_sd2=2) {set.seed(123) # Setting a seed for reproducibility# Initialize an empty data frame to store the simulated data data <-data.frame(x =numeric(), y =numeric())# Loop to create each groupfor (i in1:group_count) { x_start <-12+ (i -1) * (10/ group_count) # Stagger the start of x for each group x <-runif(points_per_group, min = x_start, max = x_start + (10/ group_count))# Apply a local positive trend within the group, but maintain the global negative trend local_intercept <- global_intercept + global_slope * (x_start + (10/ (2* group_count))) +rnorm(1, mean =0, sd = noise_sd) y <- local_intercept + group_slope[i] * (x - x_start) +rnorm(points_per_group, mean =0, sd = noise_sd2)# Combine this group with the overall dataset group_data <-data.frame(x = x, y = y,group=i) data <-rbind(data, group_data) }return(data)}# generate simulated datadata_int <-simulate_grouped_trend(group_count =4,points_per_group =10,global_slope =-2,global_intercept =100,group_slope =c(6,4,2,1),noise_sd =5,noise_sd2=2)# set group to factordata_int$group <-factor(data_int$group)# Design matrix of random effectZ <-model.matrix(~0+data_int$group)# Construct the model matrix 'X' for the fixed effect 'x' using data from 'data_int'.X <-model.matrix(~x, data=data_int)# get groups (random effects)groups <-unique(data_int$group)y<-data_int$yc<-matrix(c(0,1),ncol=2)# Define the log-likelihood function (as negative log-likelihood)log_reml <-function(theta) { D <-diag(x = theta[2], ncol =length(groups), nrow =length(groups)) I <-diag(1, nrow =nrow(X), ncol =nrow(X)) V <- theta[1] * (I + Z %*% D %*%t(Z)) Beta <-solve(t(X) %*%solve(V) %*% X) %*%t(X) %*%solve(V) %*% yreturn(c(log(det(V)) +log(det(t(X) %*%solve(V) %*% X)) +t(y - X %*% Beta) %*%solve(V) %*% (y - X %*% Beta)))}theta<-optimization::optim_nm(fun = log_reml, k =2, start =c(1,1),maximum=FALSE, tol =0.0000000000001)$partheta<-matrix(theta,ncol =2)# Compute the Hessian at the estimateshessian_matrix <-hessian(log_reml, theta)Sigma <-2*solve(hessian_matrix)# define g matrixg <-function(theta) { D <-diag(x = theta[2], ncol =length(groups), nrow =length(groups)) I <-diag(1, nrow =nrow(X), ncol =nrow(X)) V <- theta[1] * (I + Z %*% D %*%t(Z))return((c) %*%solve(t(X) %*%solve(V) %*% X) %*%t(c))}# Calculate the gradient of a function by numerical approximationg_grad<-as.matrix(grad(g,theta))var_S2<-t(g_grad)%*%Sigma%*%g_gradS2<-g(theta)d <- (2* S2^2) / var_S2D <-diag(x = theta[2],ncol =length(groups),nrow =length(groups))I <-diag(1,nrow =nrow(X),ncol =nrow(X))V<-theta[1]*(I+Z%*%D%*%t(Z))Beta <-solve(t(X) %*%solve(V) %*% X) %*%t(X) %*%solve(V) %*% yprint(data.frame(df=d,t=Beta[2]/sqrt(S2),pvalue=2*pt(Beta[2]/sqrt(S2),df=d,lower.tail =FALSE)))
df t pvalue
1 36.7423 4.33864 0.000107513
Compare this to lmerTest results:
model<-lmer(y~x+(1|group),data=data_int,REML =TRUE)library(emmeans)trends <-emtrends(model, var ="x", lmer.df ="satterthwaite")print(summary(trends, infer =TRUE))
We get similar results and this concludes our chapter on math behind mixed models.
Summary
In this section, we went through how mixed models works starting from OLS all the way to GLS and estimation and hypothesis testing. Please note that some of the derivations are very in efficient way of solving the equations in practice there are highly optimized methods to solve the mixed models.